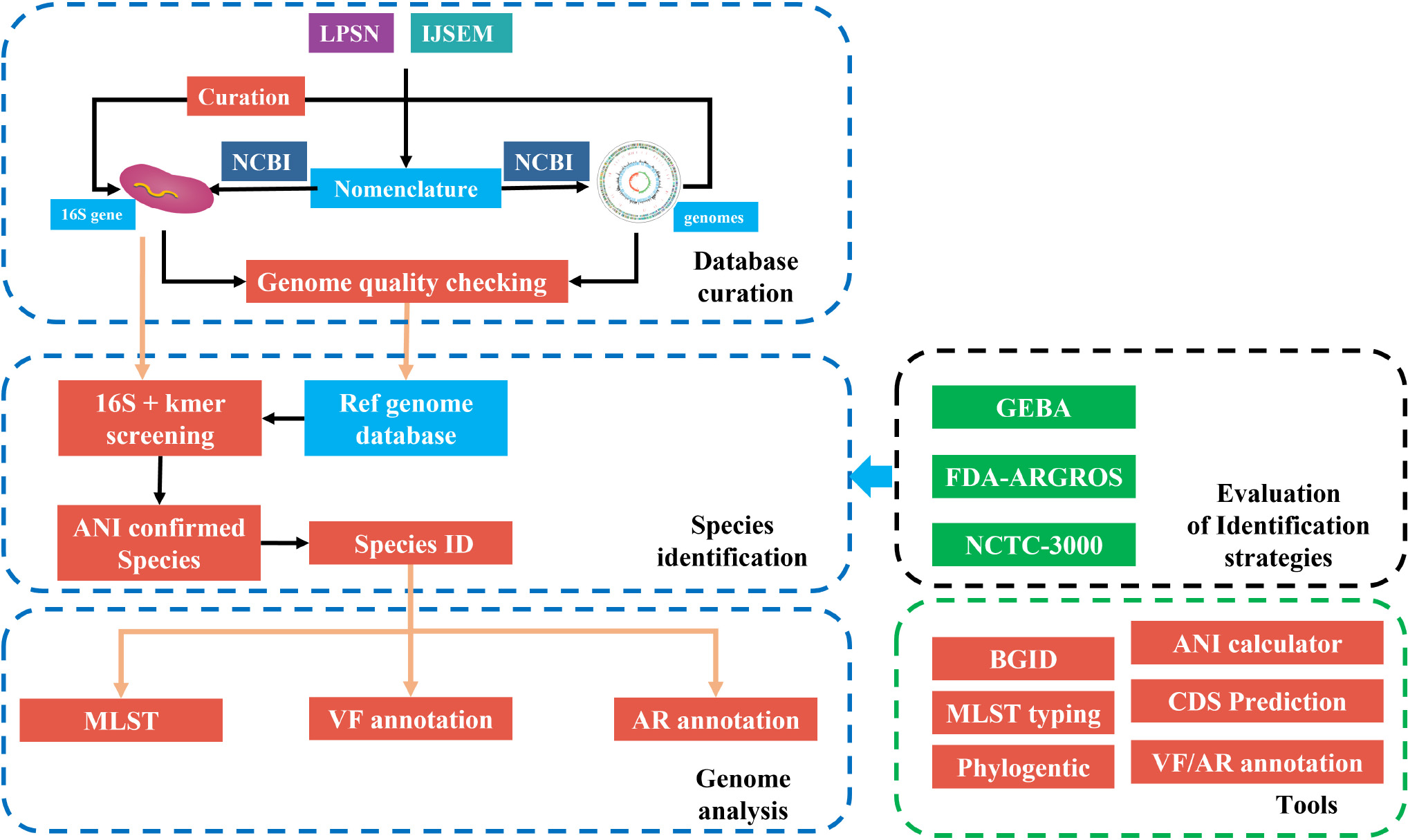
오늘도 나의 2021년 11월 하순을 뜨겁게 달구고 있는 fIDBAC과 관련한 이야기를 써 내려가려고 한다. fIDBAC 파이프라인에서는 16S rRNA 서열 분석과 KmerFinder를 통해서 top 20 closest genome을 고르고, 이를 대상으로 fastANI를 실시하여 일정 컷오프를 통과하는 결과로부터 query genome이 어떠한 species에 해당하는지를 판별하여 그 정보를 OUTDIR/fastANISpecies 파일에 출력한다. example/example.fa를 사용한 경우는 이러하다.
$ cat example_2021_11_25_08_20_15/fastANISpecies
Salmonella enterica
fastANISpecies 파일에 여러 라인이 기록될 수도 있을까? fIDBAC.pl(v20181126)의 133번째 줄에서 다음과 같이 fastANISpecies 파일의 첫 줄만을 뽑아내도록 한 것을 보면 가끔 그런 일이 생기기도 하는 모양이다.
my $template=`head -n 1 $result/fastANISpecies`;chomp $template;
fastANISpecies 파일을 만드는 과정에 대해서도 살펴볼 것이 많지만 이에 대해서는 나중에 알아보기로 하고, 오늘은 fIDBAC.pl이 이 파일을 이용하는 다음 단계에 관해서 탐구해 보자. 이 단계에서 fIDABAC.pl 스크립트는 표준 출력으로 다음을 내보낸다.
Salmonella enterica...Salmonella enterica...
마치 강도에 피습당한 피해자가 '나를 칼로 찌른 놈은 아무개였어...'하고 간신히 내뱉고는 숨을 거두는 영화의 한 장면같다. 똑같은 종명(Salmonella enterica)를 두 번에 걸쳐서 출력한 것으로 보이지만 앞의 것은 $name 변수이고 뒤의 것은 $template 변수이다. 어느 종에 대한 MLST 분석을 해야 하는지 결정하는 열쇠가 되는 것이 바로 $name이다.
config_db.txt에서 설정한 LPSN(Species.tax 파일)의 첫 번째 컬럼은 'Salmonella_enterica'와 같은 형식으로 되어 있다. 공백을 underscore로 치환한 것이다. 왜냐하면 MLST DB를 구성하는 각 종명이 디렉토리 형식으로 그대로 쓰여야 하기에, 공백을 그대로 두면 곤란하기 때문이다. 이 문자열은 최종적으로 $species 변수에 저장된다. 일단 Species.txt 파일에서 첫 컬럼을 하나씩 읽어서 underscore를 다시 공백으로 바꾸어 $name과 비교하고, 일치하는 것이 있으면 이를 OUTDIR/Taxonomy.txt에 기록한다. 이는 MLST 함수가 하는 일 중의 하나이다.
MLST 분석은 fIDBAC.pl의 199번 라인부터 시작한다.
my ($species, $flag) = split (/\t/, MLST ($template)); if ($flag == 0){ my $mlstlist = glob "$pubMLSTdb/$species/*.txt" ; system("perl $Bin/run_MLST.pipeline.pl -s $species -t $mlstlist -q $input -o $result \n"); }else{ print STDERR "This species is not exists in the pubMLST db\n"; }
여기까지 살펴보면 $template와 $name 변수가 제대로 쓰였음을 알 수 있다. pubMLSTdb가 설치된 디렉토리 하위에는 $species에 해당하는 서브디렉토리가 존재하고, 또 그 밑에 세부적인 파일들(allelic progiles & sequenes)이 있어야 한다. 정확히 말하자면 여기까지가 서론이었다.
config_db.txt에서는 pubMLSTdb의 설치 위치를 지정해 두어야 한다. 그리고 fIDBAC README.md 파일에 의하면 'Download PubMLST database here.'라고 하였다. 그러나 'here'를 클릭하면 XML 파일이 나올 뿐이다. PubMLST 공식 웹사이트의 다운로드 페이지를 가 보아도 전체 자료를 하나로 묶어서 클릭만 하면 쉽게 내려받을 수 있게 만들지 않았다. 흠... 공식으로 제공하는 API를 이용해서 활용할 재주는 나에게 없다. 어떻게 해야 오늘 날짜 기준으로 153개나 되는 데이터베이스를 한꺼번에 가져올 수 있을까? 'bactopia datasets --available_datasets'으로 확인하면 무려 683개나 되는 자료가 있다. 아마 후자의 숫자는 PubMLST가 호스팅하지 않는 다른 것까지 포함해서 그런지도 모른다.
Torsten Seemann의 mlst를 사용하여 다운로드한 자료를 쓸 수 있을까? 이는 직접 실행할 일은 별로 없고, TORMES를 통해서 이용하게 된다. 나의 경우에는 다음의 위치에 파일들이 전부 저장되어 있다.
/opt/miniconda3/envs/tormes-1.3.0/db/pubmlst
그러면 이 디렉토리를 config_db.txt의 pubMLSTdb로 설정하면 될까? 전혀 그렇지 않다. 이 디렉토리의 목록은 다음과 같다. fIDBAC.pl에서는 Salmonela_enterica라는 하위 디렉토리를 이로부터 찾으려고 할 것이지만, 실제 존재하는 디렉토리 명칭은 약칭인 senteriaca이다. 이는 pubMLST 체계에서는 공식적으로 쓰이는 문자열이지만 fIDBAC.pl은 완전한 종명을 원한다.

어쩌겠는가? 완전한 종명 체계로 pubMLST를 다운로드해 주는 유틸리티를 찾아 보아야 한다. 검색 끝에 Sanger Institute에서 개발한 mlst_check라는 것을 발견하였다. 설치는 쉽게 하였으나 역시 SSL 인증서 문제로 직장 내 전산망에서는 다운로드 명령('download_mlst_databases')이 먹히질 않았다. 이를 우회하는 가장 간단한 방법은 노트북 컴퓨터로 집에서 설치한 뒤 직장으로 가지고 나와서 복사하는 것이다.
이제 fIDBAC이 잘 실행되겠지... 그러나 이는 잘못된 기대였다. T. Seemann의 mlst 명령을 이용한 것과 Sanger의 mlst_check를 이용한 것은 종명 서브디렉토리뿐만 아니라 그 하위의 파일 구조도 다르다는 것을 발견하였다. Salmonalle enterica의 예를 들어 보자.
- T. Seemann의 스타일: senterica 디렉토리 하위에 aroC.tfa dnaN.tfa hemD.tfa...의 파일이 있음
- Sanger의 스타일: Salmonella_enteria 디렉토리 하위에 profiles/profiles_csv와 alleles/alleles_fasta 두 개의 파일이 있음. 이는 fIDBAC에 의해 쓰이기가 곤란하다. 왜냐하면 '$mlstlist = glob "$pubMLSTdb/$species/*.txt'라는 코드를 상기해 보라.