Long read assembly에서 유래한 contig를 정리하여 염색체 형태로 완성된 염기서열을 얻는데 circlator만큼 편한 것은 없다. Circlator가 하는 일은 의외로 복잡하다. 원형의 replicon을 다 커버하고 끝부분에서 남는 서열(즉 앞부분에 해당하는 염기서열이 뒤에서 다시 나타나는)을 제거한 뒤 dnaA 유전자가 첫번째 ORF가 되도록 방향을 바꾸는 것만이 전부가 아니다. 만약 약간의 gap이 남아있다면 long read로부터 조립을 하여 이어주고, major contig 내부에 포함될만한 짧은 contig가 있다면 이를 병합하는 등의 일도 수행한다. 그렇게 때문에 circlator를 실행할 때에는 assembly와 더불어 long read(raw data)가 항상 필요한 것이다.
만약 말단에 겹칩이 확인되어 circularization이 확실시되는 contig가 있다고 하자. 양 끝에서 발견되는 말단을 제거하는 일만을 하고 싶지만 raw read에 해당하는 것이 없는 상황을 생각해 볼 수 있다. 그러면 minimus2 circularization pipeline을 따르면 된다고 하는데, 이때 필요한 amos가 골칫거리이다.
Bioconda의 circlator 패키지 레시피를 보면 amos 3.1.0 상이 필요하며, 파이썬은 3 이상이 필요하다. 하지만 실제 conda install circlator를 하면 amos는 저절로 깔리지 않는다. Amos는 고약하게도 파이썬 2.7까지만 작동한다.
AMOS는 whole genome assembly software의 모음이다. bank라는 독특한 데이터 체계를 사용하고 있으며, 나도 이를 이용하여 유전체를 조립한 뒤 hawkeye로 조립물의 시각화를 해 본 경험이 있다. 워낙 오래 전에 만들어진 프로그램이라서 파이썬 3 환경에서 작동하도록 개선이 되리라는 기대를 하기 어렵다.
그러면 어떻게 하면 될까? circlator의 minimus2 파이프라인에서 필요로하는 것은 toAmos와 minimus2 두 가지가 전부이다. 일단 amos를 파이썬 2.7 기반의 환경에 설치한 다음, 이 두 가지 스크립트를 실행 경로가 있는 곳에 추가하고, 파이썬 3 기반의 환경에서 circlator minimus2를 실행하면 될 것 같았다.
양 끝에 겹침을 인위적으로 도입한 대장균 K-12 MG1655의 유전체 서열을 만들어서 테스트를 해 보았다. 이어지지를 않는다. 왜 그럴까? 메시지를 찾아보니 show-coords가 제대로 작동하지를 않은 것이었다. toAmos와 minumus2 중 show-coords와 delta-filter를 내부적으로 부르는 것은 minimus2이다. minimus2를 열어보니 이 두 가지 실행파일의 경로가 /usr/local/bin/로 설정된 것이었다. 이를 제대로 고쳐주니 minimus2 파이프라인이 제대로 돌아가기 시작했다.
bioconda를 통해 배포되는 생명정보 분석용 프로그램이 이제는 족히 수천 가지는 될 것이다. 이들 사이에 의존성이 항상 완벽하게 맞아 떨어지는 것은 아니니 개별적인 사안에 대해서는 적절한 꼼수를 찾이 않을 수가 없다.
2019년 10월 29일 화요일
2019년 10월 23일 수요일
두 개의 계통수를 비교하는 tanglegram 그리기
같은 자료를 각각 다른 방법으로 처리하여 만들어낸 두 개의 계통수를 비교하기 위하여 같은 tip을 서로 연결한 그림을 tanglegram이라고 한다. 우리말로 옮기면 '엉킴그림' 또는 '엉킨그림' 정도가 될 것이다. R에서 dendextend 패키지의 tanglegram() 함수를 사용하면 원하는 그림을 그릴 수 있을 것 같은데, R을 쓰려면 이런 형태의 자료를 다루는 방법을 근본에서부터 공부해야 하니 당장 활용하기에는 매우 번거롭다. 스크립트를 별도로 만들지 않고 tanglegram을 그릴 방법이 없을까?
구글에게 물어보았다. Dendroscope라는 프로그램을 쓰면 된다고 한다. 나는 그동안 FigTree와 iTOL server를 주로 사용해 왔는데, 계통수를 다루는 프로그램 목록에 하나를 더 추가하게 되었다.
https://www.ncbi.nlm.nih.gov/pubmed/22780991
튀빙엔 대학교(Eberhard Karls Universität in Tübingen) 소속의 연구자가 개발한 툴이다. 튀빙엔(튀빙겐?) 대학은 초창기 메타게놈 분석 도구로 잘 알려진 MEGAN(MEtaGenome Analyzer, version 6 link)가 만들어진 곳이고, Dendrogram과 개발자가 같다(Huson DH). 튀빙엔 대학교는 1477년에 세워진 오래되고 유명한 학교로서 프리드리히 미셔가 19세기에 DNA를 처음 발견한 것도 이곳에서였다.
튀빙엔 대학교가 위치한 소도시 튀빙엔에 대한 여행 정보는 쉽게 검색이 가능하다.
튀빙겐, 독일에서 공부한다면 바로 이런 도시에서...
멋진 곳에서 멋진 연구 성과가 나오는 것이 맞을까? 매우 궁금하다.
Dendrscope를 이용하여 tanglegram을 그리는 방법은 다음의 링크에 상세히 설명되어 있다.
How to do a Dendroscope tanglegram
대장균의 유전체를 이용하여 roary에서 만든 core gene alignment 기반 트리(fasttree)와 accessory gene 기반 바이너리 트리를 비교하는 tanglegram을 그려 보았다. 이만하면 훌륭하다! Publication quality까지 이르도록 매만지려면 조금 더 기능을 알아보아야 되겠지만.

구글에게 물어보았다. Dendroscope라는 프로그램을 쓰면 된다고 한다. 나는 그동안 FigTree와 iTOL server를 주로 사용해 왔는데, 계통수를 다루는 프로그램 목록에 하나를 더 추가하게 되었다.
https://www.ncbi.nlm.nih.gov/pubmed/22780991
Syst Biol. 2012 Dec 1;61(6):1061-7. doi: 10.1093/sysbio/sys062. Epub 2012 Jul 10.
Dendroscope 3: an interactive tool for rooted phylogenetic trees and networks.
Author information
- 1
- Department of Computer Science, Center for Bioinformatics (ZBIT), University of Tübingen, 72076 Tübingen, Germany. daniel.huson@uni-tuebingen.de
튀빙엔 대학교(Eberhard Karls Universität in Tübingen) 소속의 연구자가 개발한 툴이다. 튀빙엔(튀빙겐?) 대학은 초창기 메타게놈 분석 도구로 잘 알려진 MEGAN(MEtaGenome Analyzer, version 6 link)가 만들어진 곳이고, Dendrogram과 개발자가 같다(Huson DH). 튀빙엔 대학교는 1477년에 세워진 오래되고 유명한 학교로서 프리드리히 미셔가 19세기에 DNA를 처음 발견한 것도 이곳에서였다.
튀빙엔 대학교가 위치한 소도시 튀빙엔에 대한 여행 정보는 쉽게 검색이 가능하다.
튀빙겐, 독일에서 공부한다면 바로 이런 도시에서...
멋진 곳에서 멋진 연구 성과가 나오는 것이 맞을까? 매우 궁금하다.
Dendrscope를 이용하여 tanglegram을 그리는 방법은 다음의 링크에 상세히 설명되어 있다.
How to do a Dendroscope tanglegram
대장균의 유전체를 이용하여 roary에서 만든 core gene alignment 기반 트리(fasttree)와 accessory gene 기반 바이너리 트리를 비교하는 tanglegram을 그려 보았다. 이만하면 훌륭하다! Publication quality까지 이르도록 매만지려면 조금 더 기능을 알아보아야 되겠지만.

2019년 10월 22일 화요일
우분투 가상머신에 아나콘다 최신판을 설치하기가 왜 이렇게 힘이 들까?
11월에 한국바이오협회에서 주관하는 유전체분야 맞춤의료 기술인력 양성 교육에 강사로 참여하게 되었다. 지난 2016년에 KOBIC 주관 교육에서 강의를 한지 꼭 3년만의 일이다. 마이크로바이옴 시대가 활짝 열리면서 단일 미생물 유전체의 해독과 분석 교육에 대한 수요는 많이 줄어든 느낌이다. 왜냐하면 요즘은 시퀀싱 업체에 미생물 유전체 시퀀싱을 맡기면 genome assembly와 annotation까지를 다 해 주기 때문이다. 물론 약간의 추가 서비스 요금은 받게 될 것이다.
'맡기면 누군가 해 주는 것'의 시대가 되니 기본 원리를 이해하려고 애쓸 필요가 별로 없어진 것이 현실이다. 그래도 기본 개념과 역사에 대해서 어느 정도는 알아야 한다는 것이 나의 철학이다. 시퀀싱 서비스 업체에 전화를 걸어서 소비자로서 원하는 것을 얻고 궁금증을 해소하기 위해 다그치는 것에만 익숙해졌을 뿐이다. 비유하자면 최소한 파워포인트의 '슬라이드'라는 말이 어디에서 기원했는지는 알아야 할 것 아니겠는가? 슬라이드 환등기나 오버헤드 프로젝터, 타자기를 실제로 본 적이 없는 사람이 점점 많아지듯 말이다.
실습을 위한 서버의 테스트 및 사전 설정은 다음주부터 진행하기로 하였으므로, 당장은 노트북에 VirtualBox로 CentOS 7.6을 가상머신으로 설치하여 원하는 환경이 잘 만들어지는지 점검하기로 하였다. 설치 후 yum update를 하니 release 7.7이 되었다. 이제 남은 작업을 해 볼까? 이렇게 고생이 시작되었다...
'맡기면 누군가 해 주는 것'의 시대가 되니 기본 원리를 이해하려고 애쓸 필요가 별로 없어진 것이 현실이다. 그래도 기본 개념과 역사에 대해서 어느 정도는 알아야 한다는 것이 나의 철학이다. 시퀀싱 서비스 업체에 전화를 걸어서 소비자로서 원하는 것을 얻고 궁금증을 해소하기 위해 다그치는 것에만 익숙해졌을 뿐이다. 비유하자면 최소한 파워포인트의 '슬라이드'라는 말이 어디에서 기원했는지는 알아야 할 것 아니겠는가? 슬라이드 환등기나 오버헤드 프로젝터, 타자기를 실제로 본 적이 없는 사람이 점점 많아지듯 말이다.
실습을 위한 서버의 테스트 및 사전 설정은 다음주부터 진행하기로 하였으므로, 당장은 노트북에 VirtualBox로 CentOS 7.6을 가상머신으로 설치하여 원하는 환경이 잘 만들어지는지 점검하기로 하였다. 설치 후 yum update를 하니 release 7.7이 되었다. 이제 남은 작업을 해 볼까? 이렇게 고생이 시작되었다...
VirtualBox guest additions의 설치가 안된다
Kernel module build 과정에서 자꾸 에러가 난다. 모든 패키지를 업데이트하고 커널 빌드에 필요한 것도 다 갖추어진 상태인지 거듭 확인을 해 보아도 소용이 없었다. VirtualBox의 버전을 6.x로 올려서 겨우 해결이 되었다. CentOS 7에서는 기본적으로 네트워크 인터페이스가 부팅 시 꺼진 상태이기 때문에 설정을 다시 찾아서 연결하는 번거로움이 있다. 게스트 OS에 잡힌 마우스 포인터를 해제하는 키는 뭐로 설정을 해야 되는가? 노트북 컴퓨터용 키보드는 101/104 키와 관계가 있던가?
최신 anaconda 배포본(anaconda3 2019.10)이 설치되지 않는다
설치용 파일(.sh)을 다운로드하여 bash로 실행하면 파일 압축 해제를 시작하는가 싶더니 전혀 진행이 되지 않았다. 무엇이 문제일까? Anaconda installer archive에서 작년 12월 버전부터 하나씩 배포판을 받아서 설치를 해 보았다. 2019.07까지는 문제가 없는데 유독 2019.10만 설치가 되지를 않았다. 이것을 확인하는데 꽤 많은 시간이 걸렸다. 정말 황당무계한 것은 이 문제는 윈도우 10 호스트에 VirtualBox로 설치한 CentOS 7에서만 벌어진다는 것이다. 온전히 CentOS가 설치된 서버에서는 어떤 배포판 버전을 쓰든 잘 설치가 된다.
리눅스 생활이 벌써 몇십년째인데 설치는 여전히 어렵다! 과거의 경험(겨우 두어달 전에 진행했던 일이라 해도)이 현재의 문제를 해결하는데 큰 도움이 되지 않는 일이 종종 발생한다.
이러한 어려움 속에서도 bioconda가 나를 살렸다는 결론에는 변함이 없다. 관리자 권한을 얻을 필요 없이 필요한 환경을 전부 구축할 수 있다는 것이 놀랍기만 하다.
2019년 10월 19일 토요일
낙선재 누마루 밑의 벽체의 빙렬문(氷裂紋)
가을 햇살이 좋던 주말 오후, 아내와 함께 창덕궁을 찾았다. 지난 8월 16일에는 창덕궁 후원(예전에 비원이라 부르던 곳)을 들렀었는데 너무 더워서 창덕궁의 본 모습을 제대로 감상하지 못했었다. 마침 조선시대 과거제 재현행사를 하느라 방문객들이 제법 많았다. 경복궁은 규모가 너무 크고 덕수궁은 늘 보수단체 집회가 문앞에서 열려서 소란스러운데 비하여 창덕궁은 정말로 편안하고 아름답다는 느낌이 든다. 조선의 궁궐 중에서 창덕궁만이 유네스코가 정한 세계유산에 오른 것도 그럴만한 이유가 있을 것이다.





창덕궁 안에 유일하게 단청도 없이 사대부의 주택 형식을 갖춘 수수한(?) 집이 있으니 바로 낙선재다. 차 시음행사가 있다고 하여 기웃거려 보았으나 미리 신청을 한 방문객에 한해서 체험을 할 수 있다고 하였다. 아쉬운 마음에 툇마루에 앉아서 쉬는데 누마루 밑에 있는 벽에 기하학적인 무늬가 있는 것이 눈에 뜨였다.


낙선재를 몇 번 왔었지만 누마루 밑까지 신경을 쓰지는 않았었다. '저것은 무엇이지? 손으로 그린 것인가?' 궁금한 마음에 가까이 다가가 보았다.




그려 넣은 문양이 아니었다. 기와 같이 흙으로 빚어 구운 판을 끼워 맞추고 그 사이에 회반죽을 발라 채운 것이었다. 구운 판의 색깔도 한가지가 아니었다. 이런 기가 막힌 미적 감각이라니! 집에 돌아와서 구글을 뒤져보니 얼음이 깨진 것 같은 문양이라는 뜻의 빙렬문(氷裂紋)이라 부른다고 한다. 안쪽에 있는 아궁이에서 불똥이 튀어서 누마루에 불이 붙는 것을 방지하기 위한 구조물이라고 한다. 벽체의 한쪽 면에만 문양을 넣은 것이 아니었다. 반대편을 돌아가 보면 그 모습 그대로이다.
낙선재와 석복헌 사이의 담에 만들어진 문양은 거북이 등껍데기와 같은 귀갑문이라 한다.
능률과 편리함이란 잣대에서만 본다면 전통 건축의 형태는 현대의 '최적화'와는 거리가 멀다. 지붕에는 왜 그렇게 많은 공을 들여야 했으며, 문턱은 왜 이렇게 높게 만들어서 서둘러 통과하다가는 자칫하면 발이 걸려 넘어지게 만들었을까.


건물은 왜 대지 위에 간격을 두고 띄워 지어서 대청마루를 힘겹게 '오르게' 만들었을까. 마당에는 돌이라도 깔아서 마른 날에는 흙먼지를, 비가 내리는 날에는 진창을 피하게 만들면 얼마나 좋았을까. 그걸 다 이해하려면 나이가 더 들어야 될 것 같다. 자연에 되도록 손을 대지 않고 조화를 이루려는 정신이 전통 건축 양식에 스며들어 있다고 당장은 이해해보련다.





창덕궁 안에 유일하게 단청도 없이 사대부의 주택 형식을 갖춘 수수한(?) 집이 있으니 바로 낙선재다. 차 시음행사가 있다고 하여 기웃거려 보았으나 미리 신청을 한 방문객에 한해서 체험을 할 수 있다고 하였다. 아쉬운 마음에 툇마루에 앉아서 쉬는데 누마루 밑에 있는 벽에 기하학적인 무늬가 있는 것이 눈에 뜨였다.


낙선재를 몇 번 왔었지만 누마루 밑까지 신경을 쓰지는 않았었다. '저것은 무엇이지? 손으로 그린 것인가?' 궁금한 마음에 가까이 다가가 보았다.




그려 넣은 문양이 아니었다. 기와 같이 흙으로 빚어 구운 판을 끼워 맞추고 그 사이에 회반죽을 발라 채운 것이었다. 구운 판의 색깔도 한가지가 아니었다. 이런 기가 막힌 미적 감각이라니! 집에 돌아와서 구글을 뒤져보니 얼음이 깨진 것 같은 문양이라는 뜻의 빙렬문(氷裂紋)이라 부른다고 한다. 안쪽에 있는 아궁이에서 불똥이 튀어서 누마루에 불이 붙는 것을 방지하기 위한 구조물이라고 한다. 벽체의 한쪽 면에만 문양을 넣은 것이 아니었다. 반대편을 돌아가 보면 그 모습 그대로이다.
낙선재와 석복헌 사이의 담에 만들어진 문양은 거북이 등껍데기와 같은 귀갑문이라 한다.
 |
| 출처: [연합뉴스] 창덕궁 낙선재(2) 조선의 조형미가 응축된 장소(2014년 기사 링크) |
능률과 편리함이란 잣대에서만 본다면 전통 건축의 형태는 현대의 '최적화'와는 거리가 멀다. 지붕에는 왜 그렇게 많은 공을 들여야 했으며, 문턱은 왜 이렇게 높게 만들어서 서둘러 통과하다가는 자칫하면 발이 걸려 넘어지게 만들었을까.


 |
| 책고(冊庫). 나도 방 한칸을 채울 정도로 책을 많이 읽었으면 좋겠다. |
건물은 왜 대지 위에 간격을 두고 띄워 지어서 대청마루를 힘겹게 '오르게' 만들었을까. 마당에는 돌이라도 깔아서 마른 날에는 흙먼지를, 비가 내리는 날에는 진창을 피하게 만들면 얼마나 좋았을까. 그걸 다 이해하려면 나이가 더 들어야 될 것 같다. 자연에 되도록 손을 대지 않고 조화를 이루려는 정신이 전통 건축 양식에 스며들어 있다고 당장은 이해해보련다.
2019년 10월 17일 목요일
Bash에서 탭(tab)을 표현하기 어려운 경우의 해결 방법
'\t'로 표현되는 tab 문자는 주의를 기울이지 않으면 화면에서 출력하기가 어렵다. Perl에서는 따옴표로 둘러치면 되지만 bash에서는 이것으로는 안된다. 그래서 echo 명령어에서는 -e 옵션을 통해서 백슬래쉬(\)로 이스케이프된 문자의 번역을 하도록 만든다.
이에 대한 보다 근본적인 해결 방법이 있다. 바로 $'string'을 쓰는 것이다. $'\t'라고만 하거나 혹은 문자열 전체를 $'..'로 둘러치거나 결과는 같다.
Bash reference manual의 ANSI-C quoting 항목에서는 다음과 같이 설명하였다.
예를 들어 다음과 같이 test라는 파일을 두번째 컬럼 기준으로 정렬하는 경우를 생각해 보자. 구분자로는 탭을 사용하고자 한다. line 바로 앞에 오는 스페이스를 구분자로 써서는 안되는 것이다. 다음 사례 중 의도한 결과가 나온 것은 어느것인가?
-t \t 또는 -t\t라고 입력한 것은 오류 메시지를 출력하지는 않았으나 원하는 결과가 아님에 주의해야 한다.
첨언하자면 나는 리눅스 명령어의 옵션과 그에 부속되는 설정어를 하나로 붙여서 쓰는 것을 그다지 좋아하지 않는다. 여러 옵션을 하나로 붙이는 것, 즉 ls -l -t를 ls -lt로 쓰는 것은 지극히 정상적이고 일상적인 방법이다. 그러나 sort -k 2 file을 sort -k2 file로 쓰는 것은 선호하지 않는다. -k -2를 축약해서 -k2라고 표현하는 것은 절대 아니기 때문이다.
awk의 입력 필드 정의 옵션인 -F fs(field separator)에서 는 $'\t' 형식으로 일부러 인용 처리하지 않아도 된다는 점이 장점이다. 그저 -F '\t' 또는 -F "\t"라고만 해도 된다. -F '\t'라 해도 작동은 하지만, awk의 표준 사용법은 awk 'command' 이므로 -F에 이어서 공급해야 하는 field separator 자체를 작은 따옴표로 둘러치는 것은 별로 바람직하지 않다고 생각한다. 같은 이유에서 작은 따옴표를 사용하게 되는 -F $'\t' 표현도 썩 내키지는 않는다.
화면에 오류 메시지가 나오지 않았다고 해서 내가 짠 스크립트가 항상 제대로 돌아가고 있다고 착각하지는 말자.
$ echo 'hello\tworld' hello\tworld $ echo "hello\tworld" hello\tworld $ echo -e 'hello\tworld' hello world $ echo -e "hello\tworld" hello world
이에 대한 보다 근본적인 해결 방법이 있다. 바로 $'string'을 쓰는 것이다. $'\t'라고만 하거나 혹은 문자열 전체를 $'..'로 둘러치거나 결과는 같다.
$ echo hello$'\t'world hello world $ echo $'hello\tworld' hello world
Bash reference manual의 ANSI-C quoting 항목에서는 다음과 같이 설명하였다.
The word expands to string, with backslash-escaped characters replaced as specified by the ANSI C standard.이러한 요령을 알고 있으면 텍스트 파일을 처리하는 유틸리티에서 탭을 구분자로 지정해 줄 때 발생하는 오류에 대처할 수 있다. sort와 join 명령어에서는 -t SEP 옵션을 사용하여 구분자(SEP은 구분자로 쓰려는 문자)를 설정하는데, 탭을 구분자로 정의하려면 -t$'\t'라고 하는 것이 안전하다. 물론 이것은 bash에서 그렇다는 뜻이다.
예를 들어 다음과 같이 test라는 파일을 두번째 컬럼 기준으로 정렬하는 경우를 생각해 보자. 구분자로는 탭을 사용하고자 한다. line 바로 앞에 오는 스페이스를 구분자로 써서는 안되는 것이다. 다음 사례 중 의도한 결과가 나온 것은 어느것인가?
$ cat test [first line] 1 A [third line] 3 C [second line] 2 B $ sort -t \t -k 2 test second 1-line: 2 A first 2-line: 3 C third 3-line: 1 B $ sort -t\t -k 2 test second 1-line: 2 A first 2-line: 3 C third 3-line: 1 B $ sort -t '\t' -k 2 test sort: multi-character tab `\\t' $ sort -t'\t' -k 2 test sort: multi-character tab `\\t' $ sort -t "\t" -k 2 test sort: multi-character tab `\\t' $ sort -t"\t" -k 2 test sort: multi-character tab `\\t' $ sort -t$'\t' -k2 test third 3-line: 1 B second 1-line: 2 A first 2-line: 3 C $ sort -t $'\t' -k2 test third 3-line: 1 B second 1-line: 2 A first 2-line: 3 C
-t \t 또는 -t\t라고 입력한 것은 오류 메시지를 출력하지는 않았으나 원하는 결과가 아님에 주의해야 한다.
첨언하자면 나는 리눅스 명령어의 옵션과 그에 부속되는 설정어를 하나로 붙여서 쓰는 것을 그다지 좋아하지 않는다. 여러 옵션을 하나로 붙이는 것, 즉 ls -l -t를 ls -lt로 쓰는 것은 지극히 정상적이고 일상적인 방법이다. 그러나 sort -k 2 file을 sort -k2 file로 쓰는 것은 선호하지 않는다. -k -2를 축약해서 -k2라고 표현하는 것은 절대 아니기 때문이다.
awk의 입력 필드 정의 옵션인 -F fs(field separator)에서 는 $'\t' 형식으로 일부러 인용 처리하지 않아도 된다는 점이 장점이다. 그저 -F '\t' 또는 -F "\t"라고만 해도 된다. -F '\t'라 해도 작동은 하지만, awk의 표준 사용법은 awk 'command' 이므로 -F에 이어서 공급해야 하는 field separator 자체를 작은 따옴표로 둘러치는 것은 별로 바람직하지 않다고 생각한다. 같은 이유에서 작은 따옴표를 사용하게 되는 -F $'\t' 표현도 썩 내키지는 않는다.
화면에 오류 메시지가 나오지 않았다고 해서 내가 짠 스크립트가 항상 제대로 돌아가고 있다고 착각하지는 말자.
2019년 10월 15일 화요일
[하루에 한 R] 그룹 내의 최댓값/최솟값 구하기, 그리고 그 값을 갖는 행을 찾아내기 - dplyr 패키지
최대값·최소값이 아니라 최댓값·최솟값이 올바른 표기라 한다. 뒤에 오는 말의 첫소리가 된소리이면 사이시옷을 넣어야 한다는 것이다(링크). '북엇국'이라고 쓰기는 정말 어색한데...
행(row) 단위로 그룹을 지을 수 있는 자료가 데이터 프레임으로 주어졌다고 하자. 각 그룹 안에서 특정 컬럼의 최대 혹은 최솟값을 찾아내는 방법은 잘 알려져 있다. 예전에 작성한 [하루에 한 R] BLAST tabular output에서 best hit 뽑아내기에서는 base R을 이용한 원초적인 방법을 소개한 적이 있다. 학습 목적을 위하여 좀 더 단순한 데이터 프레임을 만들어 놓자.
A 그룹에 속하는 raw만 보고 싶다면 data[which(data$group=='A'),]라고 입력하는 것이 정석이다. which() 함수를 쓰지 않고 data[data$group=='A',]라고 쳐도 결과는 같지만 전자의 방법이 더욱 바람직하다고 생각한다.
각 그룹에 대하여 numer의 최댓값은 무엇일까? base R을 쓰려면 다음과 같이 입력하면 된다. 명령어가 끝나는 곳에서 닫아야 할 괄호가 많으니 빼먹지 말도록 하자.
반환되는 serial column을 이용하여 max값을 갖는 row의 정보를 알 수 있다. 하지만 완벽하지는 않다. 왜냐하면 공동 1위에 대한 배려가 없기 때문이다. 각 그룹에 대하여 최댓값을 갖는 row가 여럿인 경우, 어느 하나만을 반환한다.
aggregate() 함수를 쓰면 각 그룹에 대한 number 컬럼의 최댓값을 출력할 수 있다.
Hardley Wickham이 만든 dplyr 패키지(공식 문서)를 이용하면 좀 더 현명한 데이터 탐색이 가능하다. 다음의 웹사이트에 훌륭한 예제가 많다.
R: dplyr - Maximum value row in each group
Dplyr Introduction
[R] 데이터 처리의 새로운 강자, dplyr 패키지 - 강력 추천!
그러면 최초의 질문으로 돌아오자. 각 그룹별로 최대의 number 값을 갖는 row를 찾아내자. serial 컬럼을 같이 출력하게 되면 문제가 해결된다. 웹을 뒤지다가 정말 단순하고 강력한 방법을 찾아내어 여기에 소개하고자 한다. 공동 1위가 나타나서 한 그룹에 대해 복수의 row를 출력하게 되어도 상관이 없다. 위에서 do.call() 함수를 쓴 것과 serial의 값이 다르게 나온 것은 data 데이터 프레임을 중간에 새로 만들었기 때문이다. merge() 함수를 이런 곳에서 사용하다니 정말 창의적이다.
Basic R: rows that contain the maximum value of a variable
최종적으로 얻어지는 컬럼의 순서는 별로 마음에 들지는 않는다. dplyr 패키지를 사용하려면 다음과 같이 하라.
dplyr은 데이터 프레임을 다루기에 매우 유용한 패키지이다. 기초 수준의 사용법을 익혀서 나중에 별도로 글을 써야 되겠다. 실습을 위한 장난감용 데이터와 코드 몇 줄을 만들어 보았다.
dplyr과 사랑에 빠진 어느 블로거의 글을 소개한다. dplyr을 쓰는 것에 익숙해지면, apply() 계열의 함수나 aggregate() 함수를 쓸 일이 없어질 것 같다.
[R-bloggers] I fell out with tapply and in love with dplyr
행(row) 단위로 그룹을 지을 수 있는 자료가 데이터 프레임으로 주어졌다고 하자. 각 그룹 안에서 특정 컬럼의 최대 혹은 최솟값을 찾아내는 방법은 잘 알려져 있다. 예전에 작성한 [하루에 한 R] BLAST tabular output에서 best hit 뽑아내기에서는 base R을 이용한 원초적인 방법을 소개한 적이 있다. 학습 목적을 위하여 좀 더 단순한 데이터 프레임을 만들어 놓자.
> data = data.frame( letter=sample(LETTERS,1000,replace=TRUE), serial=1:1000, number=sample(1:20,1000,replace=TRUE) )
A 그룹에 속하는 raw만 보고 싶다면 data[which(data$group=='A'),]라고 입력하는 것이 정석이다. which() 함수를 쓰지 않고 data[data$group=='A',]라고 쳐도 결과는 같지만 전자의 방법이 더욱 바람직하다고 생각한다.
각 그룹에 대하여 numer의 최댓값은 무엇일까? base R을 쓰려면 다음과 같이 입력하면 된다. 명령어가 끝나는 곳에서 닫아야 할 괄호가 많으니 빼먹지 말도록 하자.
> do.call(rbind,lapply(split(data,data$letter),function(x){return(x[which.max(x$number),])})) letter serial number A A 77 20 B B 251 20 C C 473 20 ... X X 861 20 Y Y 371 20 Z Z 264 20
반환되는 serial column을 이용하여 max값을 갖는 row의 정보를 알 수 있다. 하지만 완벽하지는 않다. 왜냐하면 공동 1위에 대한 배려가 없기 때문이다. 각 그룹에 대하여 최댓값을 갖는 row가 여럿인 경우, 어느 하나만을 반환한다.
aggregate() 함수를 쓰면 각 그룹에 대한 number 컬럼의 최댓값을 출력할 수 있다.
> aggregate(data$number,by=list(data$letter),max) Group.1 x 1 A 20 2 B 20 .. 25 Y 20 26 Z 19 > aggregate(number ~ letter,data,max) letter number 1 A 20 2 B 20 .. 25 Y 20 26 Z 19
Hardley Wickham이 만든 dplyr 패키지(공식 문서)를 이용하면 좀 더 현명한 데이터 탐색이 가능하다. 다음의 웹사이트에 훌륭한 예제가 많다.
R: dplyr - Maximum value row in each group
Dplyr Introduction
[R] 데이터 처리의 새로운 강자, dplyr 패키지 - 강력 추천!
 |
| 공구 그림을 내세운 것을 보니 '디(D)플라이어'라고 발음하는 것이 맞을 것이다. |
그러면 최초의 질문으로 돌아오자. 각 그룹별로 최대의 number 값을 갖는 row를 찾아내자. serial 컬럼을 같이 출력하게 되면 문제가 해결된다. 웹을 뒤지다가 정말 단순하고 강력한 방법을 찾아내어 여기에 소개하고자 한다. 공동 1위가 나타나서 한 그룹에 대해 복수의 row를 출력하게 되어도 상관이 없다. 위에서 do.call() 함수를 쓴 것과 serial의 값이 다르게 나온 것은 data 데이터 프레임을 중간에 새로 만들었기 때문이다. merge() 함수를 이런 곳에서 사용하다니 정말 창의적이다.
Basic R: rows that contain the maximum value of a variable
> data.agg = aggregate(number ~ letter,data,max)
> data.max = merge(data.agg,data) > data.max letter number serial 1 A 20 617 2 A 20 33 3 B 20 807 4 B 20 219 5 C 19 759 6 D 20 546 ... 51 Z 19 539 52 Z 19 448 53 Z 19 542 54 Z 19 95
최종적으로 얻어지는 컬럼의 순서는 별로 마음에 들지는 않는다. dplyr 패키지를 사용하려면 다음과 같이 하라.
> library(dplyr) > data_df = tbl_df(data) > data_df %>% group_by(letter) %>% filter(number==max(number)) %>% arrange(letter) # A tibble: 52 x 3 # Groups: letter [26] letter serial number <fct> <int> <int> 1 A 38 18 2 A 364 18 3 B 135 20 4 C 33 20 5 C 650 20 6 C 661 20 7 D 471 20 8 E 647 20 9 F 292 20 10 F 537 20 # ... with 42 more rows
dplyr은 데이터 프레임을 다루기에 매우 유용한 패키지이다. 기초 수준의 사용법을 익혀서 나중에 별도로 글을 써야 되겠다. 실습을 위한 장난감용 데이터와 코드 몇 줄을 만들어 보았다.
> library(dplyr) > data = data.frame( letter=sample(LETTERS,1000,replace=TRUE), serial=1:1000, num1=sample(1:20,1000,replace=TRUE), num2=round(rnorm(1000,10,2),digit=0), num3=sample(0:50,1000,replace=TRUE) ) > data_df = tbl_df(data) > cols = c("num1","num2","num3") > data_df %>% group_by(letter) %>% summarise_each(funs(mean,sd),cols) # A tibble: 26 x 7 letter num1_mean num2_mean num3_mean num1_sd num2_sd num3_sd <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 A 10.7 10.2 27.2 6.37 1.72 14.8 2 B 10.7 9.93 24.3 5.33 1.91 15.0 3 C 11.9 10 21.8 5.86 1.90 14.0 4 D 10.2 10.3 24.8 5.82 1.80 16.0 5 E 9.78 10.8 27.9 5.38 1.77 16.3 6 F 10.5 9.97 25.9 5.67 1.97 14.8 7 G 10.3 9.76 24.2 5.82 2.20 15.1 8 H 11.5 10.3 23.2 5.75 2.09 16.0 9 I 10.7 10.4 24.9 6.53 2.17 14.5 10 J 10.6 10.0 27.7 5.67 2.15 15.2 # … with 16 more rows
dplyr과 사랑에 빠진 어느 블로거의 글을 소개한다. dplyr을 쓰는 것에 익숙해지면, apply() 계열의 함수나 aggregate() 함수를 쓸 일이 없어질 것 같다.
[R-bloggers] I fell out with tapply and in love with dplyr
2019년 10월 13일 일요일
데이터 멍잉(data munging)
'데이터 멍잉(data munging)'이라는 말을 들어 보았는가? 내가 웹에서 이 낱말을 본 것은 불과 며칠 되지 않았다. 처음에는 오타인줄 알았다. 어디서 개가 짖나? 멍멍, 멍잉...
한빛미디어에서 출간한 전희원 저 [R로 하는 데이터 시각화] 52쪽에는 이렇게 설명을 했다고 한다.
지난주에는 일주일이 넘게 계산을 했던 local InterProScan 결과물을 R로 분석하여 그래프를 그리는 일을 했었다. TSV 파일이 만들어지기는 하지만 컬럼의 수가 각 줄에 대하여 똑같지를 않아서 R의 read.table() 함수를 처음부터 쓸 수는 없었다. 대신 awk와 wc 등의 명령을 적절히 사용하여 텍스트 파일로 전환하는 일을 먼저 진행했는데, 바로 이것이 데이터 멍잉에 해당하는 일이 되겠다.
O'Reilly에서 출간한 Paul Teener의 [R Cookbook] 72쪽을 보면 이런 내용이 나온다.
'data wrangling R'로 구글에서 검색을 해 보면 꽤 많은 유튜브 동영상이 나온다. 몇 개를 골라서 공부해 보는 것도 좋을 것이다. R Studio Inc.의 Garrett Grolemund가 만든 다음 4개의 연속 동영상에서 시작해 보겠다. Garret은 R for Data Science 및 R Markdown의 공저자이며, 해들리 위컴이 그의 박사과정 지도교수였다고 한다!
Pt. 1: What is data wrangling? Intro, motivation, outline, setup(여기에서는 munging을 분명히 '먼징'으로 발음하였다)
Pt. 3: Data manipulation tools: `dplyr`
Pt. 4: Working with two datasets: b ind, set operations, and joins
한빛미디어에서 출간한 전희원 저 [R로 하는 데이터 시각화] 52쪽에는 이렇게 설명을 했다고 한다.
멍잉(munging)은 전처리, 파싱, 필터링과 같이 데이터를 이리저리 핸들링한다는 뜻이다..사실 이 단어는 컴퓨터로 데이터를 처리하는 사람들 사이에서 많이 쓰이는 따끈따끈한 신조어이다.데이터 멍잉은 데이터 랭글링(data wrangling)과 같은 뜻이라 한다. 그런데 이 신조어의 발음이 과연 '멍잉'이 맞을까? 구글에서 발음을 검색해 보면 '먼깅', '먼징' 등 일정하지가 않다. 신뢰도가 높아 보이는 웹 영어사전(Cambridge Dictionary)에서 munging이라는 표제어를 찾아보니 '멍잉'으로 발음한다. 의미는 the process of changing data into another format (=arrangement) so that it can be used or processed라고 하였다. munging이 현재 진행형이라면 원형은 mung이 되어야 한다. 그러나 같은 사전에 mung이라는 표제어는 없다. Merriam-Webster 사전에도 mung 혹은 munging은 올라와 있지 않으니 어지간히 최근에 생겨난 신조어임에 틀림이 없다. 다음 사전에서 mung은 '(미 속어) [프로그램 등을] 개조하다, 대폭 변경하다. 망가뜨리다'로 풀이하였다. 데이터 멍잉은 일부러 일을 망치려고 하는 것은 아닌데 말이다. 어쨌든 데이터 멍잉은 데이터 파싱(parsing, 구문 분석) 또는 데이터 프리프로세싱(preprocessing)과는 약간 다른 의미를 갖는다.
지난주에는 일주일이 넘게 계산을 했던 local InterProScan 결과물을 R로 분석하여 그래프를 그리는 일을 했었다. TSV 파일이 만들어지기는 하지만 컬럼의 수가 각 줄에 대하여 똑같지를 않아서 R의 read.table() 함수를 처음부터 쓸 수는 없었다. 대신 awk와 wc 등의 명령을 적절히 사용하여 텍스트 파일로 전환하는 일을 먼저 진행했는데, 바로 이것이 데이터 멍잉에 해당하는 일이 되겠다.
O'Reilly에서 출간한 Paul Teener의 [R Cookbook] 72쪽을 보면 이런 내용이 나온다.
R is not a great tool for preprocessing data files, however. The authors of S assumed you would perform that munging with some other tool: perl, awk, sed, cut, paste, whatever floats your boats. Why should you they duplicate that capability? ... Let R do what R does best.나도 이 글에 100% 동의한다.
'data wrangling R'로 구글에서 검색을 해 보면 꽤 많은 유튜브 동영상이 나온다. 몇 개를 골라서 공부해 보는 것도 좋을 것이다. R Studio Inc.의 Garrett Grolemund가 만든 다음 4개의 연속 동영상에서 시작해 보겠다. Garret은 R for Data Science 및 R Markdown의 공저자이며, 해들리 위컴이 그의 박사과정 지도교수였다고 한다!
Pt. 1: What is data wrangling? Intro, motivation, outline, setup(여기에서는 munging을 분명히 '먼징'으로 발음하였다)
Pt. 2: Tidy data and tidyr
Pt. 3: Data manipulation tools: `dplyr`
2019년 10월 12일 토요일
모바일보호 서비스 앱은 이름을 바꾸어야 한다
파견 근무지(사기업)에서 일을 하게 되면서 기업이 요청한 보안 프로그램 두 가지를 휴대폰에 설치하게 되었다. 이런 종류의 프로그램을 MDM(mobile device management) 솔루션이라 부른다. 이를 설치하고 작동시키면 회사 안에 있을 경우 카메라가 작동이 되지 않는다. 실제로는 더 깊숙한 수준에서 휴대폰을 제어하고 있고, 당연히 사용자의 동의를 거쳐서 설치를 하게 된다. 물론 그 동의 절차가 어떤 결과를 초래하는지 정확히 모르는 경우가 많다는 것이 문제이다.
설치된 두 가지의 프로그램은 엇비슷한 이름을 하고 있었다. 하나는 '모바일보안'이고 다른 하나는 '모바일보호 서비스(삼성전용)'이었다. 편의상 이를 각각 A와 B라 부르기로 한다. 앞의 것(A)은 사용자가 직접 제어할 수 있는 앱인데(실제로는 내 맘대로 작동시키는 것이 아니라 엄격한 위치 기반으로 움직임) 최소한 하루에 한 번을 건드려 주어야 해서 여간 불편한 것이 아니다. 설명하자면 상황은 이러하다. 아침에 출근하여 신분증을 인식기에 찍으면 찍으면 거의 즉각적으로 휴대폰의 보안 프로그램이 작동하여 카메라의 작동이 불가능해 진다. 그런데 퇴근을 하고 건물을 나깔 때에는 그렇지가 않다. 신분증을 찍어서 퇴근 상태로 만들면 일단 보안이 해제되지만, 계단이나 엘리베이터로 건물 내부를 통과하여 밖으로 나가자마자 그 짧은 시간 동안 휴대폰의 위치를 점검하여 다시 보안이 걸리는 것이다. 퇴근 후 건물을 빠져나와 불과 십 미터 정도밖에 가지 않았는데 휴대폰에서는 '보안이 적용되습니다'라는 알림 소리가 들린다. 그래서 회사에서 충분히 멀리 떨어진 곳까지 가거나 아예 집까지 와서 보안을 수동으로 해제해야 비로소 카메리를 쓸 수 있다.
만일 내가 좀 더 현명한 개발자였다면, 신분증을 인식기에 찍어서 퇴근 처리를 하고 난 뒤 5분이나 10분 쯤 지나서 자동으로 휴대폰의 현재 위치를 파악하여 회사에 있지 않음이 확인되면 보안을 해제하게 만들 것이다. 왜 매번 퇴근 후에 수작업으로 보안을 해제하게 만들었을까? 이렇게 함으로 인하여 유발되는 보안을 위협할 수 있는 다른 부작용이 발생할지는 모르겠으나, 개발자에게 개선을 요구해 볼 생각이다.
이 프로그램은 앞서 말했듯이 사용자가 직접 작동할 수 있지만, 더불어 설치하는 두번째 앱(B)은 '모바일보호 서비스'라는 애매모호한 이름을 갖고 있으면서 무소불의의 권력을 휘두른다. 설치된 프로그램 목록에서 이것을 볼 때마다 모바일용 V3와 같이 내 기기를 '보호'하는 프로그램으로 착각을 했었다. 앱 이름에서 풍기는 느낌이 딱 그러하지 않은가.

하지만 실상은 이렇다.
모바일 기기를 통한 정보 유출을 방지하기 위하여 기업/기관에서 요청하여 만들어진 프로그램으로서 해당 기업/기관(개발사 입장에서는 고객)에서 고용되어 일하거나 방문하는 사람의 모바일 기기에 강제적으로 설치하는 - 회사의 보안앱과 더불어 - 보안 프로그램.
이것이 정확한 설명이다. 그러나 정작 구글 플레이에서는 보면 프로그램에 대한 설명이 눈에 잘 뜨이지 않는 곳에 있으며 이마저도 충분하지 않다. 이 프로그램을 개발한 사람은 고객사에는 최선을 다하여 프로그램에 대한 정보를 제공하겠지만, 정작 이 프로그램을 강제로 설치해야만 하는 사람에게는 친절히 설명을 할 동기가 주어지지 않는다. 다음은 PC에서 구글 플레이를 접속하여 찾은 정보이다. 일반적인 앱이라면 구글 플레이에서 검색만 해도 이것이 무엇을 위한 앱인지 친절히 설명을 해 놓았을 것이다.

이 앱의 리뷰를 보면 설치 후 캡쳐 등이 되지 않아서 고생을 한 사람들의 불평이 하나 가득이다. 내가 보기에는 구글 플레이에서 앱의 이름만 보고서 보안에 도움이 되리라 생각하고 설치를 한 뒤 부작용을 겪는 것 같다. 위의 설명에서 이 앱은 '절대 단독으로 실행되어 동작될 수 없으며...;라 하였다. 그러면, A 앱이 먼저 설치되지 않은 상태에서는 모바일보호 서비스 앱(B)의 설치 또는 구동이 되지 않게 만들었다는 뜻인가? 불만이 섞인 리뷰를 보면 그렇지는 않은 것 같다. 이 앱의 원래 목적을 정확히 모르고 설치를 한 사람이 절대적으로 많은 것 같다는 뜻이다.
다시 말해서 A가 필요한 사람 - 정확히 말하자면 보안이 필요한 기업/기관에 고용관계 혹은 방문을 위해서 A를 설치하도록 요청받은 사람 - 이 아닌 경우에도 모바일보호 서비스(B)가 단독으로 설치가 되는 것 같고, 이런 상태에서 B를 설치하면 휴대폰 작동에 심각한 제한이 걸려서 고생을 하게 된다. A는 구글 플레이에서 검색이 되지 않는다. 고객사에서 배포하거나 다운로드 사이트를 알려주지 않으면 일반인은 이를 일부러 설치할 수 없다(설치할 이유도 없다). 그런데 구글 플레이에서 우연히 '모바일보호 서비스'라는 이름의 앱(B)을 발견하여 휴대폰의 보안에 도움이 될 것으로 오해하고 설치하면 그야말로 지옥을 맛보게 될 것이다.
혹은 MDM 솔루션이 설치된 휴대폰을 제대로 삭제하지 않고 중고로 판매한 경우 이를 구입한 사람은 생고생을 하게 된다. 웹을 검색해 보니 공장 초기화 정도로 해결이 되지 않는다고 한다. MDM 솔루션을 개발한 사람은 당연히 이렇게 만들었을 것이다.
따라서 모바일보호 서비스의 개발자인 지란지교시큐리티에서는 다음의 조치를 취해야 한다고 생각한다.

이제는 필수품이나 다름이 없는 모바일 기기를 보안이 절실한 기업 입장에서는 어떻게 통제해야 될까? 개인의 권리는 또 어떻게 찾아야 할까? 정말 어려운 문제가 아닐 수 없다.
설치된 두 가지의 프로그램은 엇비슷한 이름을 하고 있었다. 하나는 '모바일보안'이고 다른 하나는 '모바일보호 서비스(삼성전용)'이었다. 편의상 이를 각각 A와 B라 부르기로 한다. 앞의 것(A)은 사용자가 직접 제어할 수 있는 앱인데(실제로는 내 맘대로 작동시키는 것이 아니라 엄격한 위치 기반으로 움직임) 최소한 하루에 한 번을 건드려 주어야 해서 여간 불편한 것이 아니다. 설명하자면 상황은 이러하다. 아침에 출근하여 신분증을 인식기에 찍으면 찍으면 거의 즉각적으로 휴대폰의 보안 프로그램이 작동하여 카메라의 작동이 불가능해 진다. 그런데 퇴근을 하고 건물을 나깔 때에는 그렇지가 않다. 신분증을 찍어서 퇴근 상태로 만들면 일단 보안이 해제되지만, 계단이나 엘리베이터로 건물 내부를 통과하여 밖으로 나가자마자 그 짧은 시간 동안 휴대폰의 위치를 점검하여 다시 보안이 걸리는 것이다. 퇴근 후 건물을 빠져나와 불과 십 미터 정도밖에 가지 않았는데 휴대폰에서는 '보안이 적용되습니다'라는 알림 소리가 들린다. 그래서 회사에서 충분히 멀리 떨어진 곳까지 가거나 아예 집까지 와서 보안을 수동으로 해제해야 비로소 카메리를 쓸 수 있다.
만일 내가 좀 더 현명한 개발자였다면, 신분증을 인식기에 찍어서 퇴근 처리를 하고 난 뒤 5분이나 10분 쯤 지나서 자동으로 휴대폰의 현재 위치를 파악하여 회사에 있지 않음이 확인되면 보안을 해제하게 만들 것이다. 왜 매번 퇴근 후에 수작업으로 보안을 해제하게 만들었을까? 이렇게 함으로 인하여 유발되는 보안을 위협할 수 있는 다른 부작용이 발생할지는 모르겠으나, 개발자에게 개선을 요구해 볼 생각이다.
이 프로그램은 앞서 말했듯이 사용자가 직접 작동할 수 있지만, 더불어 설치하는 두번째 앱(B)은 '모바일보호 서비스'라는 애매모호한 이름을 갖고 있으면서 무소불의의 권력을 휘두른다. 설치된 프로그램 목록에서 이것을 볼 때마다 모바일용 V3와 같이 내 기기를 '보호'하는 프로그램으로 착각을 했었다. 앱 이름에서 풍기는 느낌이 딱 그러하지 않은가.

하지만 실상은 이렇다.
모바일 기기를 통한 정보 유출을 방지하기 위하여 기업/기관에서 요청하여 만들어진 프로그램으로서 해당 기업/기관(개발사 입장에서는 고객)에서 고용되어 일하거나 방문하는 사람의 모바일 기기에 강제적으로 설치하는 - 회사의 보안앱과 더불어 - 보안 프로그램.
이것이 정확한 설명이다. 그러나 정작 구글 플레이에서는 보면 프로그램에 대한 설명이 눈에 잘 뜨이지 않는 곳에 있으며 이마저도 충분하지 않다. 이 프로그램을 개발한 사람은 고객사에는 최선을 다하여 프로그램에 대한 정보를 제공하겠지만, 정작 이 프로그램을 강제로 설치해야만 하는 사람에게는 친절히 설명을 할 동기가 주어지지 않는다. 다음은 PC에서 구글 플레이를 접속하여 찾은 정보이다. 일반적인 앱이라면 구글 플레이에서 검색만 해도 이것이 무엇을 위한 앱인지 친절히 설명을 해 놓았을 것이다.

이 앱의 리뷰를 보면 설치 후 캡쳐 등이 되지 않아서 고생을 한 사람들의 불평이 하나 가득이다. 내가 보기에는 구글 플레이에서 앱의 이름만 보고서 보안에 도움이 되리라 생각하고 설치를 한 뒤 부작용을 겪는 것 같다. 위의 설명에서 이 앱은 '절대 단독으로 실행되어 동작될 수 없으며...;라 하였다. 그러면, A 앱이 먼저 설치되지 않은 상태에서는 모바일보호 서비스 앱(B)의 설치 또는 구동이 되지 않게 만들었다는 뜻인가? 불만이 섞인 리뷰를 보면 그렇지는 않은 것 같다. 이 앱의 원래 목적을 정확히 모르고 설치를 한 사람이 절대적으로 많은 것 같다는 뜻이다.
다시 말해서 A가 필요한 사람 - 정확히 말하자면 보안이 필요한 기업/기관에 고용관계 혹은 방문을 위해서 A를 설치하도록 요청받은 사람 - 이 아닌 경우에도 모바일보호 서비스(B)가 단독으로 설치가 되는 것 같고, 이런 상태에서 B를 설치하면 휴대폰 작동에 심각한 제한이 걸려서 고생을 하게 된다. A는 구글 플레이에서 검색이 되지 않는다. 고객사에서 배포하거나 다운로드 사이트를 알려주지 않으면 일반인은 이를 일부러 설치할 수 없다(설치할 이유도 없다). 그런데 구글 플레이에서 우연히 '모바일보호 서비스'라는 이름의 앱(B)을 발견하여 휴대폰의 보안에 도움이 될 것으로 오해하고 설치하면 그야말로 지옥을 맛보게 될 것이다.
혹은 MDM 솔루션이 설치된 휴대폰을 제대로 삭제하지 않고 중고로 판매한 경우 이를 구입한 사람은 생고생을 하게 된다. 웹을 검색해 보니 공장 초기화 정도로 해결이 되지 않는다고 한다. MDM 솔루션을 개발한 사람은 당연히 이렇게 만들었을 것이다.
따라서 모바일보호 서비스의 개발자인 지란지교시큐리티에서는 다음의 조치를 취해야 한다고 생각한다.
- B앱의 명칭을 '모바일 보안' 등으로 바꾸어야 한다. 앗, 그러나 A앱이 이미 이 이름을 쓰고 있다. 어쨌든 일반 사용자가 단순히 휴대폰을 보호해주는 앱으로 오해햐여 설치하는 일이 없게 해야 한다.
- A 프로그램을 먼저 깔지 않은 상태에서는 기술적으로 모바일보호 솔루션이 설치되지 않게 해야 한다. 어떤 일이 생길지 몰라서 다른 휴대폰으로 일부러 테스트를 할 수는 없었다.
- 고객사가 아니라 구글 플레이를 통해 이 앱을 찾은 일반 사용자에게 충분한 정보를 제공해야 한다.
- 정상적인 앱 제거 방법을 알려야 한다. 물론 보안이 필요한 기억/기관의 피고용자가 악의적으로 제거하기는 못하게 해야 하니 고민스러울 것이다.
구글 플레이의 앱 리뷰에 이러한 취지의 글을 남기기는 했는데 과연 수용될지는 모르겠다.

이제는 필수품이나 다름이 없는 모바일 기기를 보안이 절실한 기업 입장에서는 어떻게 통제해야 될까? 개인의 권리는 또 어떻게 찾아야 할까? 정말 어려운 문제가 아닐 수 없다.
2019년 10월 11일 금요일
`...`과 $(...)을 사용한 command substitution, 그리고 process substitution
표준 QWERTY 키보드에서 숫자 1의 왼쪽에 있는 키를 누르면 `가 찍힌다. 아래의 그림에서 왼쪽 위 모서리에 있는 키 말이다. `는 backtick, grave accent 또는 어려운 한자어로는 억음 (抑音)부호라고 부른다.

Bash에서는 이것으로 어떤 명령어를 둘러싸면(`command`) 그 출력물을 바꾸어서 내어 놓는다. 가독성을 높이기 위해 요즘은 $(command)로 대체하는 추세라고 한다. 이를 command substitution이라 한다. 내가 바이블처럼 읽는 Mark G. Sobell의 A Practical Guide to the Unix System 3판(발간된 해인 1995년에 구입함)에서 처음 접한 것이 `command` 방식이라서 $(command) 방식을 처음 보고는 이게 도대체 무엇인지를 몰라서 의의하게 생각했었다.
Sobell 선생께서는 은퇴를 하셨는지 블로그에는 2012년 3월을 마지막으로 새 글이 없다. 트위터 계정도 갖고 계시다.
제목과는 다른 주제가 되겠지만 리다이렉션은 종종 혼동을 초래한다. 이런 것은 이해하는데 아무런 문제가 없다.
하지만 이것은 어떠한가?
틀림없이 파일이 인수명으로 있어야 할 위치에 <(command)가 위치하였다. 무슨 의미인지는 어렴풋하게 이해할 수 있다. 괄호안에 위치한 명령어의 표준출력이 이름 없는 파일에 먼저 쓰여지고, 이 파일이 join 명령어의 인수로 작용하는 것으로 생각하면 된다. 이러한 용법을 bash 매뉴얼에서는 무엇이라고 하는가? 찾아보니 process substitution이라고 부른다. 매뉴얼에서는 <(list) 또는 >(list)의 용법이 있다고 설명을 하였다. 구글에서 국문으로 프로세스 치환을 검색하니 KLDP의 웹페이지를 제외하면 별다른 정보가 없지만, 영문 검색으로는 많은 사례가
그러면 >(list)는 무엇을 뜻할까? 이것은 조금 더 어렵다. 문제는 process substitution이 POSIX 표준을 준수하지는 않는다는 것이다(참조 링크).
이해는 약간 되는 듯하지만 다른 사람에게 설명을 하라면 아직 부족하다. 내가 머리가 나쁜 것인가? 흠...

Bash에서는 이것으로 어떤 명령어를 둘러싸면(`command`) 그 출력물을 바꾸어서 내어 놓는다. 가독성을 높이기 위해 요즘은 $(command)로 대체하는 추세라고 한다. 이를 command substitution이라 한다. 내가 바이블처럼 읽는 Mark G. Sobell의 A Practical Guide to the Unix System 3판(발간된 해인 1995년에 구입함)에서 처음 접한 것이 `command` 방식이라서 $(command) 방식을 처음 보고는 이게 도대체 무엇인지를 몰라서 의의하게 생각했었다.
Sobell 선생께서는 은퇴를 하셨는지 블로그에는 2012년 3월을 마지막으로 새 글이 없다. 트위터 계정도 갖고 계시다.
제목과는 다른 주제가 되겠지만 리다이렉션은 종종 혼동을 초래한다. 이런 것은 이해하는데 아무런 문제가 없다.
$ ls > file.txt
하지만 이것은 어떠한가?
$ join <(sort file1.txt) <(sort file2.txt)
틀림없이 파일이 인수명으로 있어야 할 위치에 <(command)가 위치하였다. 무슨 의미인지는 어렴풋하게 이해할 수 있다. 괄호안에 위치한 명령어의 표준출력이 이름 없는 파일에 먼저 쓰여지고, 이 파일이 join 명령어의 인수로 작용하는 것으로 생각하면 된다. 이러한 용법을 bash 매뉴얼에서는 무엇이라고 하는가? 찾아보니 process substitution이라고 부른다. 매뉴얼에서는 <(list) 또는 >(list)의 용법이 있다고 설명을 하였다. 구글에서 국문으로 프로세스 치환을 검색하니 KLDP의 웹페이지를 제외하면 별다른 정보가 없지만, 영문 검색으로는 많은 사례가
그러면 >(list)는 무엇을 뜻할까? 이것은 조금 더 어렵다. 문제는 process substitution이 POSIX 표준을 준수하지는 않는다는 것이다(참조 링크).
이해는 약간 되는 듯하지만 다른 사람에게 설명을 하라면 아직 부족하다. 내가 머리가 나쁜 것인가? 흠...
2019년 10월 9일 수요일
일상 20191009
영조정순왕후가례도감의궤를 담은 컵. 세밀한 기록화가 상당히 디자인적이다. 화음이 없는 국악(대신 '농'이라 불리는 떨림이 있다), 그리고 원근법의 개념이 담겨있지 않는 한국화를 서양의 그것과 비교하여 어떻게 견주어야 하는가에 대해 늘 고민이 많았다. 이에 대해서는 언젠가 진지하게 글로 풀어봐야 할 것이다. 아직 독서 기록을 남기지 않은 진중권의 [미학 오디세이]에서도 동양의 미에 대해서는 전혀 다루지를 않아서 아쉽기만 하다.

시계가 사람을 섬기는가, 사람이 시계를 섬기는가? 오토매틱 와인딩의 기계식 시계를 항상 착용할 수 있는 상태로 보관하기 위해 와치와인더라는 물건을 쓴다는 것을 알고는 참 의아하게 생각했었다. 손목의 움직임을 대신하기 위해 시계를 풀어놓은 다음에는 전기를 사용하는 기계를 가동한다니! 그러는 나는 태양빛으로 작동하는 카시오의 터프솔라 시계를 구입하고는 하루 종일 햇볕을 찾아다니고 있지 않은가? 심지어 LED 스탠드에 시계를 비추기도 하고... 관리 상태에 따라 7-10년을 사용한다고 하지만, 되도록 만충전 상태(H level)를 유지하기 위해 10년 내내 이렇게 신경을 써야 한다면 차라리 2-3년에 한번 배터리를 갈아주는 쿼츠 시계가 더 낫지 않을까? 외출 시에도 소매가 시계를 덮지 않도록 신경을 쓰는 것도 우습다. 더군다나 팔이 짧아서 늘 소매가 길게 늘어지게 옷을 입고 다니는 나는(새 재킷을 살 때 항상 소매 길이 수선을 하지는 못하므로) 이러한 점에서는 불리하다. 어쩌면 터프솔라의 충전에 과도하게 신경을 쓰는 것일지도 모른다.
 |
| 카시오 삼형제. 구입 순서는 오른쪽부터. |
독서 기록 - 조지 오웰의 [1984]
영국이나 미국에서는 고등학생 시절에 누구나 다 읽는다는 조지 오웰(본명은 에릭 아더 블레어, 1930-1968)의 소설 1984를 읽었다. 미래 고도 사회의 밝은 면을 조금 보여주다가 통제받는 암울한 현실을 소개하면서 이야기가 전개될 것으로 생각했는데 그게 아니었다. 아마도 올더스 헉슬리의 소설 [멋진 신세계]이것도 아직 읽지 않음)의 제목에서 어떤 선입견을 가졌던 모양이다. 처음부터 무겁게 시작하여 시종일관 그 분위기는 달라지지 않는다. 주인공 윈스턴 스미스가 줄리아를 만나서 사랑에 빠져 있던 것은 순간이었고, 사상 경찰에 붙잡힌 후 당하는 고통의 순간은 책을 읽다가 차라리 고개를 돌리고 싶었다.
1984년에 태어난 사람은 벌써 30대 중반이 된 2019년 10월을 살고 있는 지금, 아직 우리는 빅 브러더와 같은 무지막지한 국가 권력을 경험하지는 않았다. 그러나 텔레스크린이 아니더라도 치안을 위한다는 이유로 어디에나 CCTV가 설치되어 있고, 비록 그것을 강제하지는 않으나 개인이 인터넷에 남기는 정보를 이용하여 언제든지 신상이 털릴 각오를 하고 있어야 한다. 정보의 독점은 국가가 아니라 기술을 갖춘 기업 - 한때는 혁신의 상징이었고 모든 이가 그곳에서 일하고 싶어하는 - 에 의해 이루어진다. 그리고 넘쳐나는 정보는 사실의 판단을 흐리게 만든다. 이 소설에서 윈스턴의 직업은 바로 당의 지령에 맞추어 과거의 신문 등 기록을 고치는 일 아니던가. 예를 들어 일제 강점기가 우리에게 진정한 근대화를 가져다 준 시기라고 당에서 정의를 새로 내리기로 한다면 과거의 기록을 찾아내어 핍박과 탄압을 받았던 흔적을 지우고 새 기사를 넣어서 다시 배포하는 것이다. 현재를 지배하면 곧 과거를 지배하는 것이고, 과거를 지배하는 것은 미래를 지배하게 된다!
한때 이 책은 반공주의를 고무하려는 '국가 권력'에 의해서 널리 읽히기를 권장받기도 했었다. 사실 그것은 옳지 않다. 조지 오웰은 투철한 민주사회주의자였고 이 책을 통해 비판하려는 것은 전체주의였다. 전체주의는 어떠한 정치 체제의 틀을 쓰고도 올 수 있으니 말이다.
조지 오웰의 시대에는 기업이 세상을 지배하는 세상이 오리라고 생각하지 못했을 것이다. 스마트폰을 거부하고 아직까지 고집스레 피처폰을 쓰는 사람들(심지어 극소수지만 휴대전화를 쓰지 않는 사람도 있으니)은 우리 주변의 윈스턴인지도 모른다.
밑바닥부터 사회 생활을 경험한 조지 오웰이 남긴 다른 작품들을 구해서 읽어보고 싶어졌다. 그는 19세 때부터 미얀마에서 5년 동안 경찰 생활을 하다가 영국 제국주의의 식민 지배에 대한 회의를 품고 돌아오기도 했고 작가가 되기로 결심한 뒤 프랑스 파리에서 영어 개인교사와 접시닦이 일을 했으며, 런던에서는 부랑자들과 어울려 룸펜 생활을 한 바 있고, 스페인 내란을 취재하기 위해 바르셀로나로 갔다가 무정부주의 시민군에 가담하기도 했다. 심지어 2차대전이 발발하자 입대를 원했으나 건강상의 이유로 거절당하자 민방위 부대에 자원하여 들어가서 군수공장에서 열성적으로 일을 했다고 한다. 결국은 1945년 종군기자로 유럽 전선으로 가서 나치스 독일의 붕괴를 목격하였다.
 |
| 최윤영 옮김. '빅 브러더'는 첫 쪽부터 등장한다. |
1984년에 태어난 사람은 벌써 30대 중반이 된 2019년 10월을 살고 있는 지금, 아직 우리는 빅 브러더와 같은 무지막지한 국가 권력을 경험하지는 않았다. 그러나 텔레스크린이 아니더라도 치안을 위한다는 이유로 어디에나 CCTV가 설치되어 있고, 비록 그것을 강제하지는 않으나 개인이 인터넷에 남기는 정보를 이용하여 언제든지 신상이 털릴 각오를 하고 있어야 한다. 정보의 독점은 국가가 아니라 기술을 갖춘 기업 - 한때는 혁신의 상징이었고 모든 이가 그곳에서 일하고 싶어하는 - 에 의해 이루어진다. 그리고 넘쳐나는 정보는 사실의 판단을 흐리게 만든다. 이 소설에서 윈스턴의 직업은 바로 당의 지령에 맞추어 과거의 신문 등 기록을 고치는 일 아니던가. 예를 들어 일제 강점기가 우리에게 진정한 근대화를 가져다 준 시기라고 당에서 정의를 새로 내리기로 한다면 과거의 기록을 찾아내어 핍박과 탄압을 받았던 흔적을 지우고 새 기사를 넣어서 다시 배포하는 것이다. 현재를 지배하면 곧 과거를 지배하는 것이고, 과거를 지배하는 것은 미래를 지배하게 된다!
한때 이 책은 반공주의를 고무하려는 '국가 권력'에 의해서 널리 읽히기를 권장받기도 했었다. 사실 그것은 옳지 않다. 조지 오웰은 투철한 민주사회주의자였고 이 책을 통해 비판하려는 것은 전체주의였다. 전체주의는 어떠한 정치 체제의 틀을 쓰고도 올 수 있으니 말이다.
전쟁은 평화/자유는 예속/무지는 힘
War is peace / Freedom is slavery / Ignorance is strength2 + 2 = 5라는 말도 안되는 명제를 사실로 믿게 만들고 급기야 '빅 브러더'를 사랑하게 만드는 무시무시한 힘이 아직도 작동 중인 나라가 몇 군데 있는 것 같다. 이보다 조금 더 고급스런 전략을 구사하는 곳에서는 대중이 원한다는 이유로 그냥 놔 두면서 우리가 미처 알지 못하는 방법으로 경제적 이익을 취하기에 바쁘다. 새로운 정보를 얻으려는 욕구, 지식을 나누려는 욕구, 고도의 정치적 의도를 깔고 만들어진 허위 사실을 퍼 나르려는 것... 클릭 회수가 올라갈수록 누군가는 돈을 번다. 문턱을 지키고 앉은 플랫폼 기업이 입장료를 징수하고 있는 셈이다.
조지 오웰의 시대에는 기업이 세상을 지배하는 세상이 오리라고 생각하지 못했을 것이다. 스마트폰을 거부하고 아직까지 고집스레 피처폰을 쓰는 사람들(심지어 극소수지만 휴대전화를 쓰지 않는 사람도 있으니)은 우리 주변의 윈스턴인지도 모른다.
밑바닥부터 사회 생활을 경험한 조지 오웰이 남긴 다른 작품들을 구해서 읽어보고 싶어졌다. 그는 19세 때부터 미얀마에서 5년 동안 경찰 생활을 하다가 영국 제국주의의 식민 지배에 대한 회의를 품고 돌아오기도 했고 작가가 되기로 결심한 뒤 프랑스 파리에서 영어 개인교사와 접시닦이 일을 했으며, 런던에서는 부랑자들과 어울려 룸펜 생활을 한 바 있고, 스페인 내란을 취재하기 위해 바르셀로나로 갔다가 무정부주의 시민군에 가담하기도 했다. 심지어 2차대전이 발발하자 입대를 원했으나 건강상의 이유로 거절당하자 민방위 부대에 자원하여 들어가서 군수공장에서 열성적으로 일을 했다고 한다. 결국은 1945년 종군기자로 유럽 전선으로 가서 나치스 독일의 붕괴를 목격하였다.
바로 그때 무장한 간수가 뒤에서 나타났다. 오랫동안 기다렸던 바로 그 총알이 그의 머리에 박혔다.
그는 빅 브러더의 거대한 얼굴을 올려다보았다. 저 검은 콧수염 속에 숨겨진 미소의 의미를 알아내는 데 40년이란 긴 세월이 걸렸던 것이다. 아, 잔인하고 불필요한 오해여! 아, 저 사랑이 가득한 품안을 떠나 고집부리며 스스로 택한 유형이여! 술 냄새나는 눈물이 코 옆으로 흘러내렸다. 그러나 모든 것이 잘 되었다. 싸움은 끝났다. 그는 자신과의 투쟁에서 승리를 거둔 것이다. 그는 빅 브러더를 사랑하고 있었다.[끝]
2019년 10월 7일 월요일
빛으로 시계 충전하기
무선 스마트워치 충전기가 더욱 발전하여 빛으로 충전을 한다는 뜻이 아니다. 태양전지판을 이용한 매우 고전적인 충전을 의미한다.
토토로 LED 스탠드가 수고를 하고 있다. 1시간 정도 LED 빛을 쪼여서 M에서 H 레벨로 충전시키는데 성공하였다. 그러나 M 레벨의 범위가 매우 넓다는 것을 알아야 한다. 또한 가까스로 H 레벨이 되었다 하여도 이 모델에 탑재된 5525 모듈의 경우 만충전을 시키려면 실외 태양빛(5만 lux) 조건에서 무려 8시간을 더 놓아두어야 한다. 터프솔라의 진실... 터프솔라 유저 필독!이라는 글이 매우 유용하다.

 |
| CASIO G-SHOCK GST-S310-1ADR. 5525 모듈 설명서(링크). |
공작 본능이 발동한다면 LED를 이용하여 충전기를 만들 수도 있다.
카시오(터프솔라) 시계 충전기를 만들어 보자
기존의 LED 스탠드를 사용하든 DIY로 충전기를 만들든 약간의 전기요금은 들 것이다. 태양광 충전을 사용함으로써 전지 교체 비용이 절감되는 효과를 상쇄할 정도가 되지 않을까?
지난 여름, 어느 오디오 관련 사이트에 일본인 재즈 뮤지션(우에하라 히로미)의 라이브 동영상을 올렸다가 다른 회원의 비판적인 댓글이 달린 것을 보았다.
요즘 시국에 '토토로'에 '카시오'에 관한 사진을 올리다!
이런 소소한 글을 내 블로그에 쓰는 데에도 신경을 써야 한다는 현실이 안타깝다. 그렇다고 하여 자체 검열을 한다는 것은 우스운 일이다.
터프솔라 충전용 거치대 ver. 0.1

2019년 10월 5일 토요일
크고 많을 수록 좋은 것인가
물가상승률을 고려하여 같은 가격으로 예전보다 더 많은(혹은 더 큰) 용량의 물건을 사게 되었을 때 우리는 '세상 참 좋아졌다'고 이야기한다. 만 원에 500 ml짜리 수입 캔맥주를 몇 개씩 살 수 있을 때 흡족함을 느끼는 것처럼 말이다. 나는 태생적으로 술을 잘 못하는 사람이라서 알코올이 인류에게 가져다 준 즐거움과 긍정적인 효과를 잘 모른다. 그러나 알코올이 본인을 철저히 망가뜨리고 주변 사람들을 힘들게 만드는 과정을 두 눈으로 똑똑히 봐 온 사람이기도 하다. 간단히 말해서 '취중진담'을 믿지 않으며, 권력화된 술자리 문화를 극도로 혐오한다. 높은 사람이 술잔을 채워 주어야만 술을 먹을 수 있는 것, 그리고 다른 사람의 빈 잔을 빨리 알아채고 채워줘야 하는 분위기를 좋아하지 않는다.
호기심과 업무 차원에서 숙취 현상을 학술적으로 조사해 본 일이 있다. 숙취는 술을 많이 마신 다음날, 혈중 알코올 농도가 거의 0에 가깝게 떨어진 상태에서 일어난다. 알코올 대사에서 생기는 가장 중요한 독성 물질인 아세트알데히드가 숙취의 주원인이라고 여겨지지만, 숙취 증세가 나타날 때 이 물질의 혈액내 농도 역시 그렇게 높은 상태는 아니라 한다. 그리고 알코올의 만성적 섭취에 의한 간 손상과 숙취는 또한 다르다. 가장 좋은 숙취 예방법은 물론 술을 마시지 않는 것이다.
표준 음주량(standard drink)이라는 것이 있다. 미국 알코올남용및중독 연구소(National Institute on Alcohol Abuse and Alcoholism, NIAAA)에서 정의한 표준 음주량은 다음과 같다. 순수한 에탄올 14 그람에 해당하는 음주량이 1 standard drink가 된다. 10 그람의 순수 에탄올을 1 유닛(unit)으로 정의한 문서도 찾아볼 수 있다.
남성의 경우 한번에(즉 하룻밤 술자리에) 2 standard drink(순수 알코올 24 그람)를, 여성은 1을 넘기지 말 것을 권장한다. 왜 여성에게 더 적은 음주량을 권하는가? 몸무게, 체지방, 체내 알코올 분해효소의 양 등에서 전부 여성이 불리하기 때문이다.
1 standard drink는 12온스짜리 캔맥주 하나에 든 알코올에 해당한다. 수퍼마켓 혹은 편의점 진열장에서 점점 보기 힘들어지는 355 ml 정도의 캔 말이다. 요즘은 500 ml 맥주캔이 정말 흔한데, 예전에 통용되는 '작은' 캔맥주 두 개에 해당하는 알코올이 하루의 적정 음주량이라니 애주가들은 말도 안된다고 할지 모르겠다.
일일 적정 음주량은 국가나 기관마다 제시한 수치가 조금씩 다르다. WHO에서는 남성 기준 40 그람이고 여성은 그 반이다. 미국 NIAAA의 적정 음주량보다 더 많다.
적정 음주량? 한국인 현실에는 안맞아(더 적게 마시라는 소리다)
적정 음주량 - 여기에 실린 대한가정의학회 알코올연구회 가이드라인은 조심해서 해석해야 된다. 마치 하루 소주 두 병까지는 괜찮다는 식으로 해석할 수 있기 때문이다.
다음은 주류안전기획단에서 만든 자료로서 40 그람의 알코올을 함유한 술의 종류별 용량이다.
정확한 눈금이 그려진 컵을 늘 들고 다니면서 커피도 마시고 술도 마실 수 있다면 참 좋겠다는 생각이 들었다. 최대 용량이 500 ml 정도라면 라면을 끓일 물을 계량하기에도 적당하다. 최대 용량은 500 ml이고 파이렉스로 만들어져서 적당히 튼튼하며 50 ml 단위의 눈금이 그려진 뚜껑 있는 유리잔을 누구나 들고 다니는 그날까지!(흠, 좀 무겁겠군) 하긴 요즘은 텀블러를 들고 다니는 사람이 많기는 하다.
오늘 글을 쓰게 된 것은 건강한 음주를 하자는 의도는 아니었다. 적정한 음주량을 쉽게 가늠할 수 있는 캔맥주의 사이즈가 요즘 기준으로는 작은 것이 되어버렸다는 현실에 문제를 제기하려 함이었다. 비단 맥주뿐이랴? 커피는 또 어떠한가? 점점 커지는 머그잔(정확하게 말하자면 그냥 '머그'라고 불러야 한다)의 용량은 나 같은 커피믹스 애호가에게 젓정한 물의 분량(120~150 ml)을 맞추기 아주 어렵게 만든다. 밖에서 사먹는 커피는 이보다 더 심하다. 스타벅스의 그란데 사이즈는 무려 473 ml나 된다. 대용량의 것을 사면 더 싸게 살 수 있다는 판매 전략이 먹혀 들어가는 것이다. 이는 우리의 합리적인 소비 의식을 겨냥한 것처럼 보이지만, 우리의 갈증을 해결하기에 적정한 수준을 이미 넘어버린 아이스 아메리카노의 단위 섭취량당 효용 곡선은 이미 바닥을 향해 꺾이기 시작한다. 결국은 낭비를 부르는 것이다.
전혀 다른 분야인 손목시계로 잠시 넘어가 보자. 요즘 시계는 또 얼마나 큰가? 가는 손목을 가리켜서 '난민 손목'이라고는 제발 부르지 말자. 목숨을 걸고 탈출을 감행한 사람들의 어려운 처치를 희화하하는 것에 지나지 않는다. 직경 43 밀리미터는 기본으로 채우는 요즘의 시계는 마치 손목 위에서 날 좀 봐달라고 소리를 지르는 것만 같다. 욕망(과시)과 효율 논리, 그리고 합리적이고 경제적인 판단을 내리고 있다는 믿음은 적당하게 뒤엉켜서 지속 가능한 미래를 우리 손에서 더욱 멀어지게 만든다.
소비자에게 더 많은 닭고기와 돼지고기를. 모두가 일일 일닭, 일인 일닭을 하는 그날까지! 오늘도 죄 없는 돼지들은 땅 속에 묻히고 있다.
호기심과 업무 차원에서 숙취 현상을 학술적으로 조사해 본 일이 있다. 숙취는 술을 많이 마신 다음날, 혈중 알코올 농도가 거의 0에 가깝게 떨어진 상태에서 일어난다. 알코올 대사에서 생기는 가장 중요한 독성 물질인 아세트알데히드가 숙취의 주원인이라고 여겨지지만, 숙취 증세가 나타날 때 이 물질의 혈액내 농도 역시 그렇게 높은 상태는 아니라 한다. 그리고 알코올의 만성적 섭취에 의한 간 손상과 숙취는 또한 다르다. 가장 좋은 숙취 예방법은 물론 술을 마시지 않는 것이다.
표준 음주량(standard drink)이라는 것이 있다. 미국 알코올남용및중독 연구소(National Institute on Alcohol Abuse and Alcoholism, NIAAA)에서 정의한 표준 음주량은 다음과 같다. 순수한 에탄올 14 그람에 해당하는 음주량이 1 standard drink가 된다. 10 그람의 순수 에탄올을 1 유닛(unit)으로 정의한 문서도 찾아볼 수 있다.
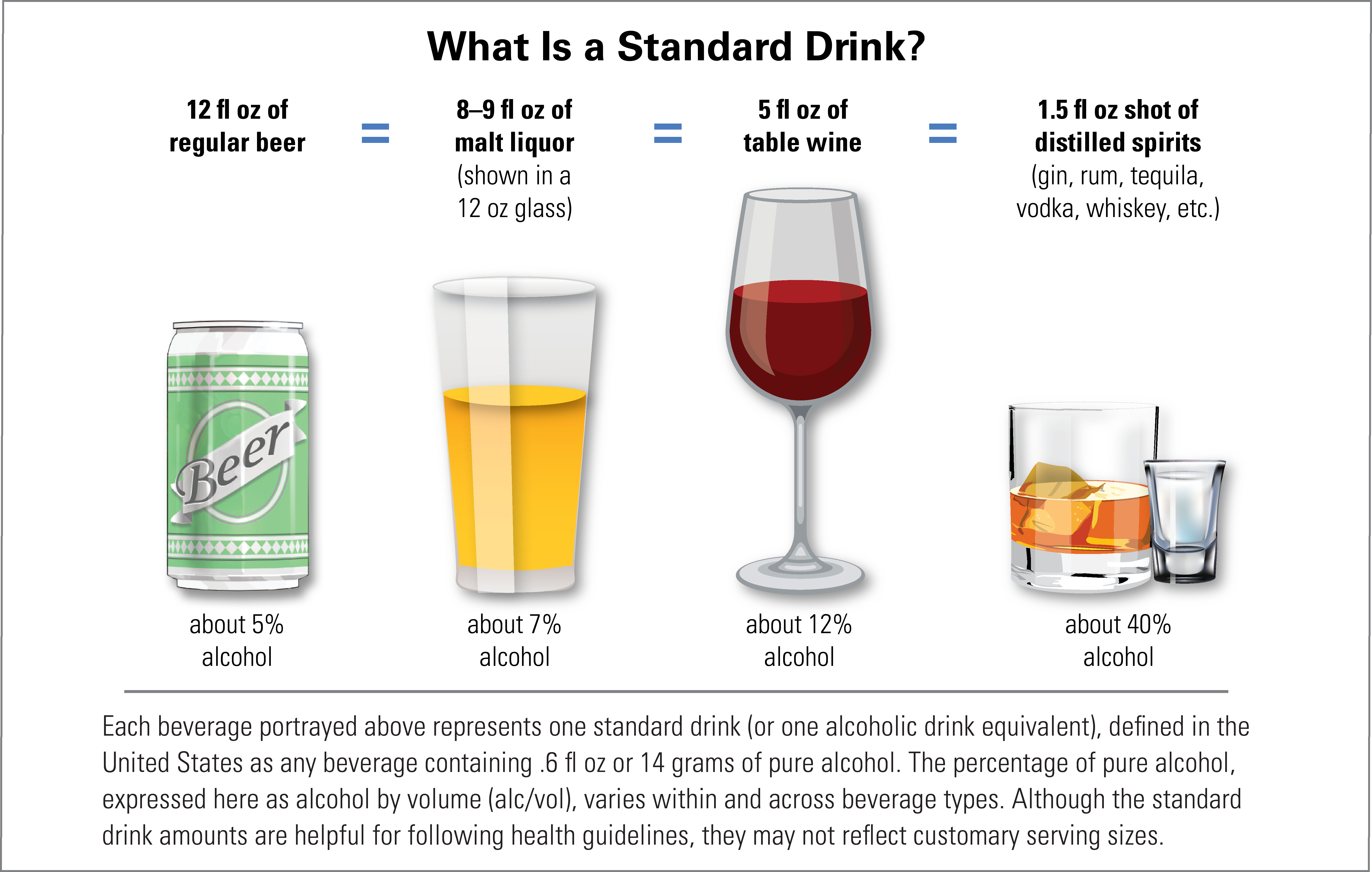 |
| 출처: https://www.niaaa.nih.gov/alcohol-health/overview-alcohol-consumption/what-standard-drink 미국 National Institute on Alcohol Abuse and Alcoholism |
1 standard drink는 12온스짜리 캔맥주 하나에 든 알코올에 해당한다. 수퍼마켓 혹은 편의점 진열장에서 점점 보기 힘들어지는 355 ml 정도의 캔 말이다. 요즘은 500 ml 맥주캔이 정말 흔한데, 예전에 통용되는 '작은' 캔맥주 두 개에 해당하는 알코올이 하루의 적정 음주량이라니 애주가들은 말도 안된다고 할지 모르겠다.
일일 적정 음주량은 국가나 기관마다 제시한 수치가 조금씩 다르다. WHO에서는 남성 기준 40 그람이고 여성은 그 반이다. 미국 NIAAA의 적정 음주량보다 더 많다.
적정 음주량? 한국인 현실에는 안맞아(더 적게 마시라는 소리다)
적정 음주량 - 여기에 실린 대한가정의학회 알코올연구회 가이드라인은 조심해서 해석해야 된다. 마치 하루 소주 두 병까지는 괜찮다는 식으로 해석할 수 있기 때문이다.
다음은 주류안전기획단에서 만든 자료로서 40 그람의 알코올을 함유한 술의 종류별 용량이다.
 |
| 자료 출처 링크 |
 |
| 아아, 그렇다고 이런 병에 손잡이를 달고 뚜껑에 구멍을 뚫어 빨대를 꽂아 다닐 수는 없지 않은가. 출처 링크 |
오늘 글을 쓰게 된 것은 건강한 음주를 하자는 의도는 아니었다. 적정한 음주량을 쉽게 가늠할 수 있는 캔맥주의 사이즈가 요즘 기준으로는 작은 것이 되어버렸다는 현실에 문제를 제기하려 함이었다. 비단 맥주뿐이랴? 커피는 또 어떠한가? 점점 커지는 머그잔(정확하게 말하자면 그냥 '머그'라고 불러야 한다)의 용량은 나 같은 커피믹스 애호가에게 젓정한 물의 분량(120~150 ml)을 맞추기 아주 어렵게 만든다. 밖에서 사먹는 커피는 이보다 더 심하다. 스타벅스의 그란데 사이즈는 무려 473 ml나 된다. 대용량의 것을 사면 더 싸게 살 수 있다는 판매 전략이 먹혀 들어가는 것이다. 이는 우리의 합리적인 소비 의식을 겨냥한 것처럼 보이지만, 우리의 갈증을 해결하기에 적정한 수준을 이미 넘어버린 아이스 아메리카노의 단위 섭취량당 효용 곡선은 이미 바닥을 향해 꺾이기 시작한다. 결국은 낭비를 부르는 것이다.
전혀 다른 분야인 손목시계로 잠시 넘어가 보자. 요즘 시계는 또 얼마나 큰가? 가는 손목을 가리켜서 '난민 손목'이라고는 제발 부르지 말자. 목숨을 걸고 탈출을 감행한 사람들의 어려운 처치를 희화하하는 것에 지나지 않는다. 직경 43 밀리미터는 기본으로 채우는 요즘의 시계는 마치 손목 위에서 날 좀 봐달라고 소리를 지르는 것만 같다. 욕망(과시)과 효율 논리, 그리고 합리적이고 경제적인 판단을 내리고 있다는 믿음은 적당하게 뒤엉켜서 지속 가능한 미래를 우리 손에서 더욱 멀어지게 만든다.
소비자에게 더 많은 닭고기와 돼지고기를. 모두가 일일 일닭, 일인 일닭을 하는 그날까지! 오늘도 죄 없는 돼지들은 땅 속에 묻히고 있다.
2019년 10월 4일 금요일
시계 수리 - 큐빅 붙이기
동대문종합시장에서 구입한 자재를 늘어놓고 작업 준비를 하면서 사진을 찍었다.

사진에 보인 손목시계는 롯데백화점 대전점에서 구입했던 포체(FOCE) 여성용 시계이다. 큐빅이 떨어져나가고 가죽줄이 닳아서 정식 수리를 맡겼던 적이 있었다. 이미 포체가 매장을 철수한 뒤라서 백화점 서비스 센터에 맡겨서 본사로 물건을 보내는 지난한 과정을 거쳐야 했다. 그러나 큐빅은 또 떨어져 나갔고 배터리가 다 되어서 시계도 멈추고 말았다. 그 이후로 아내의 시계는 몇 개가 더 늘어났으니 이제 이 시계를 그만 차라는 신의 계시인 것일까? 하지만 내 손으로 큐빅을 붙일 수만 있다면 무엇이 문제겠는가? 동대문종합시장에 가면 분명히 필요한 자재가 있을 것이라 생각하고 발품을 팔아서 비드코(http://www.beadkor.com/)라는 곳에서 딱 맞는 사이즈의 큐빅 한 봉지를 구입하였다. 붙이기 전에 바늘 같은 것으로 남아있는 접착제 찌꺼기를 제거하라는 설명도 들었다.
장신구에 널리 쓰이는 '큐빅'의 정식 명칭은 큐빅 지르코니아(cubic zirconia)이다. 화학적 성분은 이산화 지르코늄(ZrO2)이라 한다. 대표적인 제조회사는 아마도 스와로브스키일 것이다. 물론 스와로브스키에서 생산한 큐빅이 봉지에 담겨서 동대문종합시장의 한 가게에서 팔릴 것이라고 생각하지는 않는다.
접착제(E8000)도 근처 상점에서 구입하였다. 이 접착제는 금속, 유리, 도자기, 비즈, 네일스톤 등에 쓰이는 것으로 점도가 낮아서 사용하기에 좋다고 한다(설명). 처음에는 순간접착제로 붙일 생각을 했었지만 자국이 남기 쉬우무로 바람직한 선택은 아니다. 세 시간 이상을 두어야 완전히 굳는다고 한다. 웹사이트의 설명으로는 완전 경화에 하루 이상이 소요된다고 하였다.
이런 수선 작업을 처음 해 보는 것이라서 접착제를 적정량을 바르고 있는 것인지 알 수가 없었다. 큐빅을 집는 전용 집게 같은 것도 있어야 하는 것은 아닌지... 어쨌든 수선을 하고 나서 하루가 지난 다음의 모습은 이러하다.

이만하면 훌륭하다! 앞으로 큐빅이 또 떨어져 없어져도 아직 큐빅이 한봉지 가득 남았다. 이 시계를 유지보수하는데 가장 어려운 점은 색깔이 딱 맞는 스트랩을 구하기가 힘들다는 것이다. 포체 본사 수리센터에 여기에 맞는 스트랩이 얼마나 남아있을지도 이제는 알 수가 없다.
약간의 부자재 쇼핑을 마치고 들른 식당에서 점심으로 김치 칼제비를 먹었다. 꽤 알려진 맛집인지 찾는 손님마다 전부 같은 것을 주문하고 있었다. 아내는 비빔국수를 주문했는데 소면이 아닌 중면으로 끓여낸 것이었다. 맵지 않을까 걱정했는데 전혀 그렇지 않고 입맛에 잘 맞았으며 적당히 달콤하였다. 얼마전 남대문 시장에서 먹은 잔치국수도 소면이 아니고 중면이라서 약간 의외라고 생각했다. 사진으로 보면 너무 허름해서 주변에 소개하기는 미안할 지경이지만 원래 우리의 재래 시장이란 곳이 이런 분위기 아니었던가? 맛으로만 따지면 한번쯤은 더 찾아가게 될 것 같다. 조금 더 걸으면 광장시장인데, 휴일이라서 그런지 발 디딜 틈이 없었다. 대부분의 손님은 중국인 관광객 같아 보였다. 광장시장을 지나다 보니 마치 빈대떡이 한국의 대표음식이 된 듯한 느낌이었다.

다음 목적지는 세운스퀘어. 멈춘 손목시계의 배터리를 갈기 위함이다. 위에서 소개한 분홍색 포체 시계도 포함해서다. 4개의 배터리를 교체하는데 2만원이 들었다. 기다리면서 시계를 구경하였다. 진열장 한 켠에는 고풍스런 롤렉스 제품도 제법 전시되어 있었다.

간단한 노력으로 버려질 뻔한 시계에 새 생명을 불어넣게 되어 보람이 있었다.

사진에 보인 손목시계는 롯데백화점 대전점에서 구입했던 포체(FOCE) 여성용 시계이다. 큐빅이 떨어져나가고 가죽줄이 닳아서 정식 수리를 맡겼던 적이 있었다. 이미 포체가 매장을 철수한 뒤라서 백화점 서비스 센터에 맡겨서 본사로 물건을 보내는 지난한 과정을 거쳐야 했다. 그러나 큐빅은 또 떨어져 나갔고 배터리가 다 되어서 시계도 멈추고 말았다. 그 이후로 아내의 시계는 몇 개가 더 늘어났으니 이제 이 시계를 그만 차라는 신의 계시인 것일까? 하지만 내 손으로 큐빅을 붙일 수만 있다면 무엇이 문제겠는가? 동대문종합시장에 가면 분명히 필요한 자재가 있을 것이라 생각하고 발품을 팔아서 비드코(http://www.beadkor.com/)라는 곳에서 딱 맞는 사이즈의 큐빅 한 봉지를 구입하였다. 붙이기 전에 바늘 같은 것으로 남아있는 접착제 찌꺼기를 제거하라는 설명도 들었다.
장신구에 널리 쓰이는 '큐빅'의 정식 명칭은 큐빅 지르코니아(cubic zirconia)이다. 화학적 성분은 이산화 지르코늄(ZrO2)이라 한다. 대표적인 제조회사는 아마도 스와로브스키일 것이다. 물론 스와로브스키에서 생산한 큐빅이 봉지에 담겨서 동대문종합시장의 한 가게에서 팔릴 것이라고 생각하지는 않는다.
접착제(E8000)도 근처 상점에서 구입하였다. 이 접착제는 금속, 유리, 도자기, 비즈, 네일스톤 등에 쓰이는 것으로 점도가 낮아서 사용하기에 좋다고 한다(설명). 처음에는 순간접착제로 붙일 생각을 했었지만 자국이 남기 쉬우무로 바람직한 선택은 아니다. 세 시간 이상을 두어야 완전히 굳는다고 한다. 웹사이트의 설명으로는 완전 경화에 하루 이상이 소요된다고 하였다.
이런 수선 작업을 처음 해 보는 것이라서 접착제를 적정량을 바르고 있는 것인지 알 수가 없었다. 큐빅을 집는 전용 집게 같은 것도 있어야 하는 것은 아닌지... 어쨌든 수선을 하고 나서 하루가 지난 다음의 모습은 이러하다.

이만하면 훌륭하다! 앞으로 큐빅이 또 떨어져 없어져도 아직 큐빅이 한봉지 가득 남았다. 이 시계를 유지보수하는데 가장 어려운 점은 색깔이 딱 맞는 스트랩을 구하기가 힘들다는 것이다. 포체 본사 수리센터에 여기에 맞는 스트랩이 얼마나 남아있을지도 이제는 알 수가 없다.
약간의 부자재 쇼핑을 마치고 들른 식당에서 점심으로 김치 칼제비를 먹었다. 꽤 알려진 맛집인지 찾는 손님마다 전부 같은 것을 주문하고 있었다. 아내는 비빔국수를 주문했는데 소면이 아닌 중면으로 끓여낸 것이었다. 맵지 않을까 걱정했는데 전혀 그렇지 않고 입맛에 잘 맞았으며 적당히 달콤하였다. 얼마전 남대문 시장에서 먹은 잔치국수도 소면이 아니고 중면이라서 약간 의외라고 생각했다. 사진으로 보면 너무 허름해서 주변에 소개하기는 미안할 지경이지만 원래 우리의 재래 시장이란 곳이 이런 분위기 아니었던가? 맛으로만 따지면 한번쯤은 더 찾아가게 될 것 같다. 조금 더 걸으면 광장시장인데, 휴일이라서 그런지 발 디딜 틈이 없었다. 대부분의 손님은 중국인 관광객 같아 보였다. 광장시장을 지나다 보니 마치 빈대떡이 한국의 대표음식이 된 듯한 느낌이었다.

다음 목적지는 세운스퀘어. 멈춘 손목시계의 배터리를 갈기 위함이다. 위에서 소개한 분홍색 포체 시계도 포함해서다. 4개의 배터리를 교체하는데 2만원이 들었다. 기다리면서 시계를 구경하였다. 진열장 한 켠에는 고풍스런 롤렉스 제품도 제법 전시되어 있었다.

 |
| 로가디스의 드레스 워치. 사장님이 적극 추천! |
2019년 10월 2일 수요일
EzBioCloud의 사소한 오타 보고
EzBioCloud의 public genome database를 이용하다가 철자가 틀린 것을 발견하여 관리자에게 이메일로 보고하였다.

Acession은 Accession을 잘못 타이핑한 것에 틀림이 없다. 이런 사소한 오류를 고쳐달라고 피드백을 했으니 꼰대라는 소리를 들을지도 모르겠다. 웹사이트 전체를 복사하여 'GCA_' 로 시작하는 accession number를 정리하다가 우연히 발견하였다.
미생물 계통학과 유전체학 분야에서 우리나라를 대표할 수준의 서비스인데 이런 오류가 있어서야 되겠는가?
오후 네시쯤에 요청사항을 접수했다는 이메일을 받았기에 한 줄 기록을 남긴다.

Acession은 Accession을 잘못 타이핑한 것에 틀림이 없다. 이런 사소한 오류를 고쳐달라고 피드백을 했으니 꼰대라는 소리를 들을지도 모르겠다. 웹사이트 전체를 복사하여 'GCA_' 로 시작하는 accession number를 정리하다가 우연히 발견하였다.
미생물 계통학과 유전체학 분야에서 우리나라를 대표할 수준의 서비스인데 이런 오류가 있어서야 되겠는가?
오후 네시쯤에 요청사항을 접수했다는 이메일을 받았기에 한 줄 기록을 남긴다.
피드 구독하기:
덧글 (Atom)